论文阅读简记
1. NLP基础架构
Performer:Google提出的一种新的Transformer架构,提升推理与训练速度和内存利用率,arXiv,知乎,github(tf),github(torch)
Google 2020年的一篇Transformer综述,对比了当时各种Transformer变体,包括Performer、Linformer、Longformer等,arXiv,知乎
![]()
![]()
Google 2020年的另一篇Transformer综述,比较了Transformer各种变体的计算效率,下图的来源。arXiv
![]()
FLASH,最近新提出的一种Transformer变体,依然是Google出品,苏神先导复现结果较为乐观,值得尝试。arXiv,苏剑林: 科学空间
《A History from BERT to ChatGPT》,一篇由众多学者(包括Philip Yu)撰写的综述,arXiv
- 《End-to-End Transformer-Based Models in Textual-Based NLP》,一篇研究NLP中的Transformer-based系列模型成功原因、架构分类的综述,paper-page
- 《Knowing Knowledge: Epistemological Study of Knowledge in Transformers》,一篇对Transformer中的“知识”建模方式的研究,paper-page
- 《Transformers in Time Series: A Survey》,一篇研究Transformer系列模型在时序任务中的表现的综述,arXiv
FENGWU:Transformer-based的气象大模型,可以作为结构化数据、多模态数据模型的研究参考,arXiv
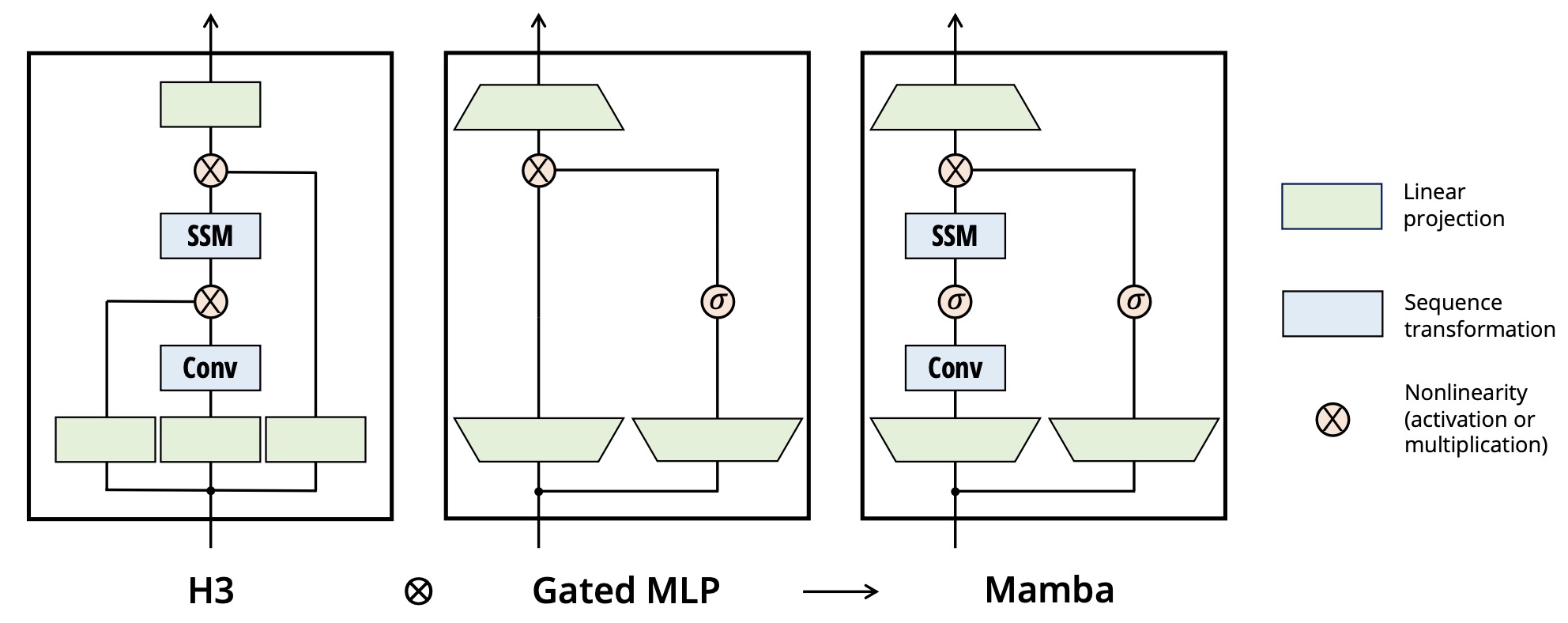
《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》,CMU与Princeton提出的新架构,有望替换Transformer,arXiv,github
![]()
《Zoology: Measuring and Improving Recall in Efficient Language Models》,系统比较卷积、线性RNN与注意力模型的研究,arXiv
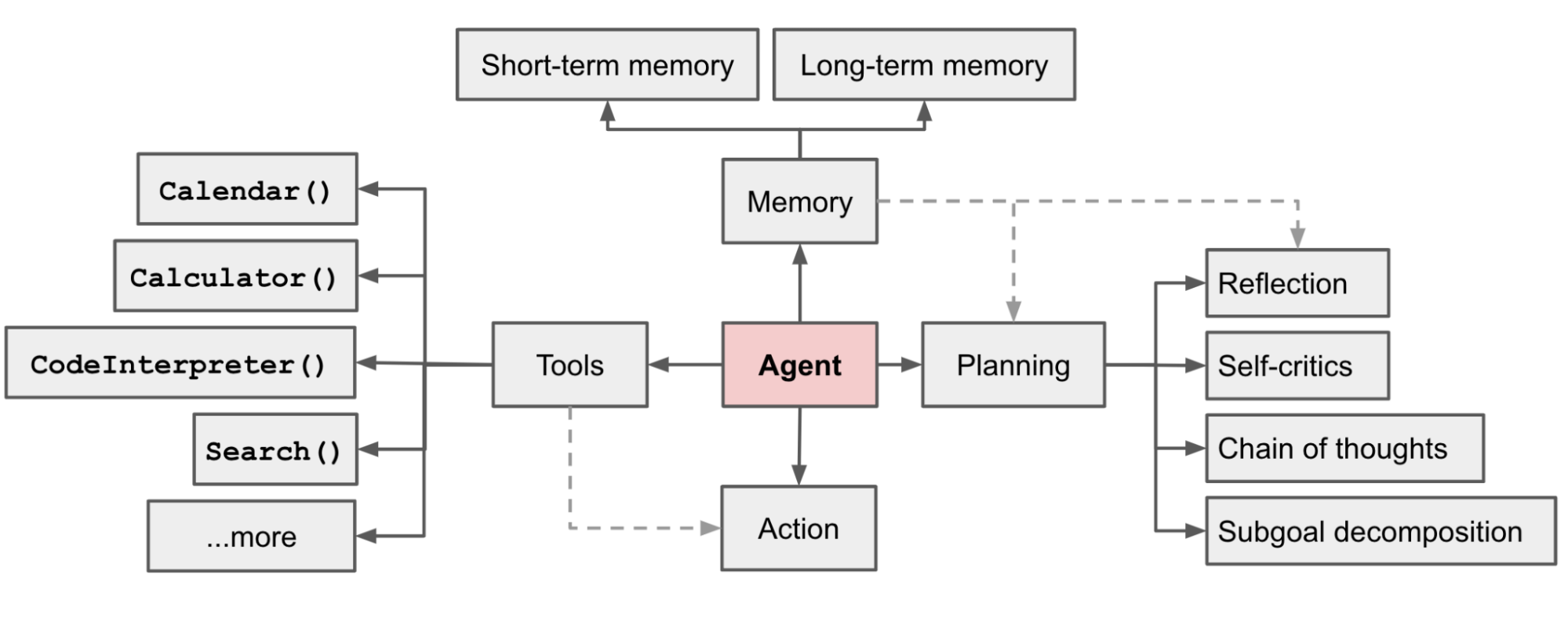
2. 智能体(Agent)
《LLM Powered Autonomous Agents》,2023年较早体系性论证Agent的blog,Blog
![]()
《Large Language Model based Multi-Agents: A Survey of Progress and Challenges》,2024年的Multi-Agent综述,arXiv
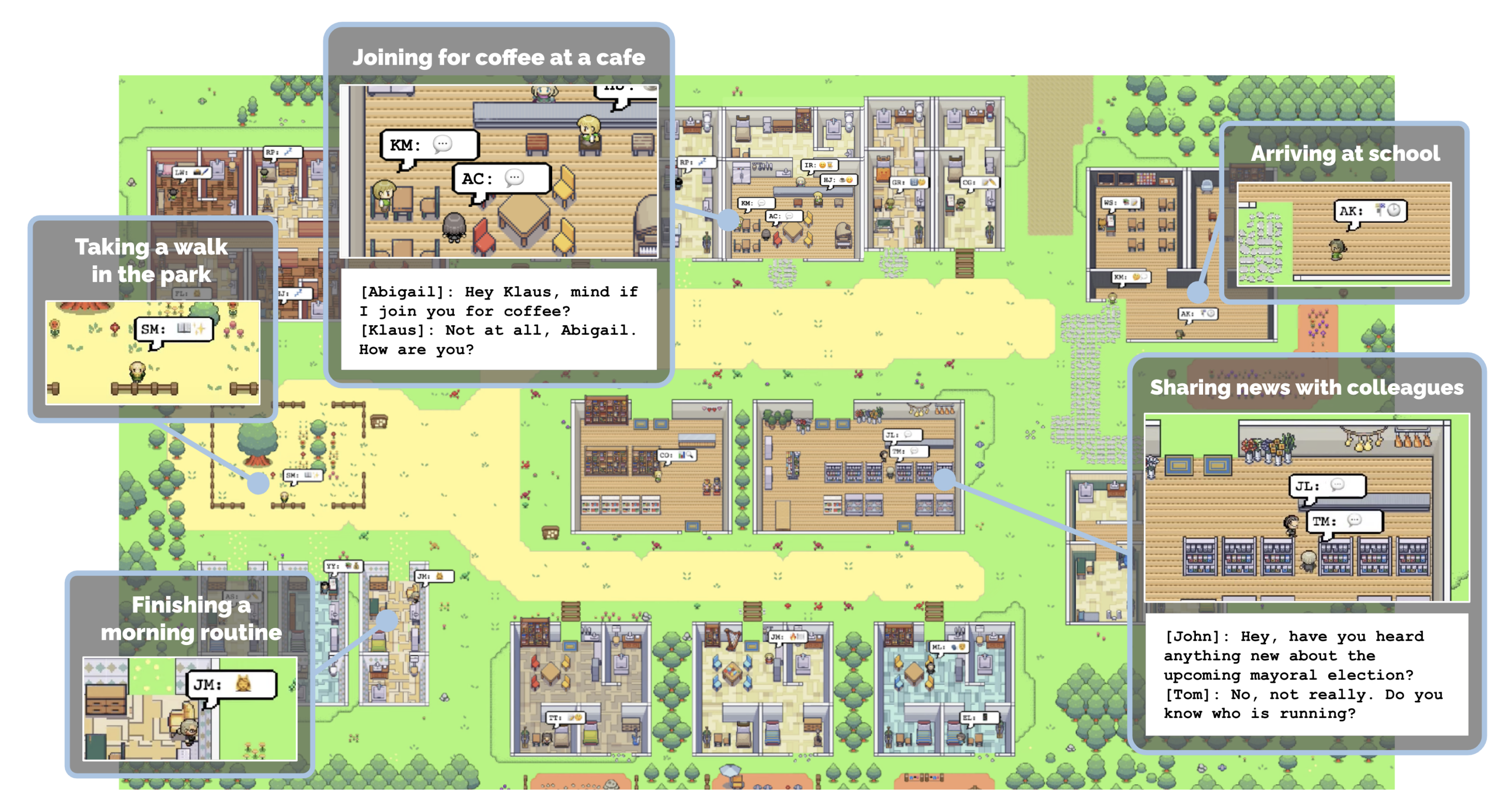
《Generative Agents: Interactive Simulacra of Human Behavior》,开源项目:斯坦福小镇。github,arXiv
![]()
《Large Language Model for Science: A Study on P vs. NP》,2023年提出的一种利用LLM解决复杂科学问题的方案,arXiv
《Multi-Agent Collaboration Mechanisms: A Survey of LLMs》,2025年科克大学发布的多智能体系统综述,arXiv
3. 统计建模范式与LLM
《Large statistical learning models effectively forecast diverse chaotic systems》
研究发现大型统计学习模型在混沌系统中表现良好,arXiv
《Commonsense Reasoning for Conversational AI:A Survey of the State of the Art》
一篇归纳总结用对话式AI做常识推理的研究的综述,arXiv
《Statistical Modeling: The Three Cultures》
《Emergent Abilities of Large Language Models》,对于涌现能力的初始研究,arXiv
《Progress Measures for Grokking via Mechanistic Interpretability》,关于涌现能力的另一个研究,值得阅读,arXiv
《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》,清华开源的中文LLM,当前普遍反馈效果最优秀的中文LLM,arXiv,github
《Are Emergent Abilities of Large Language Models a Mirage?》,斯坦福对涌现能力的质疑,arXiv
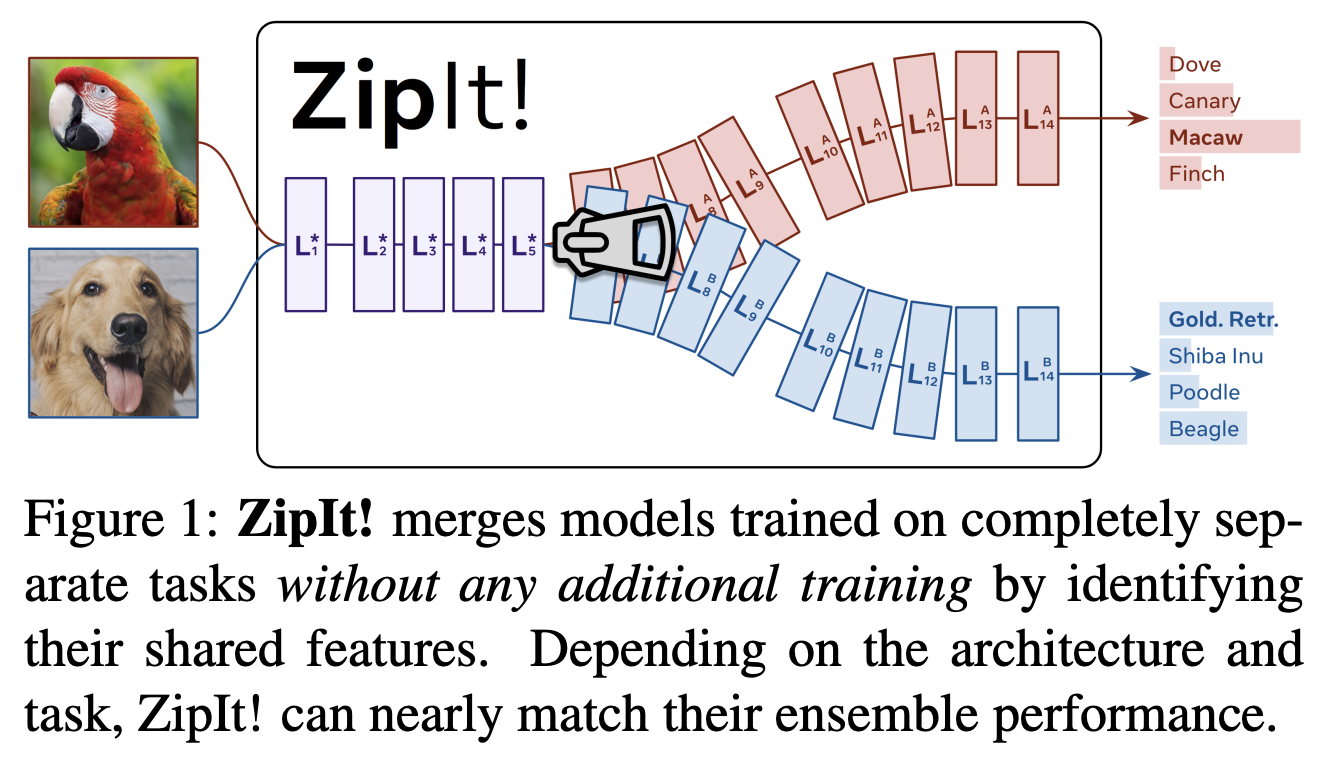
《ZipIt! Merging Models from Different Tasks without Training》,arXiv
![]()
北京甲骨易公司出的一个LLM中文任务评测数据集——MMCU,arXiv
![]()
《AutoML-GPT:Automatic_Machine_Learning_with_GPT》,利用GPT作为大脑,调度各子能力进行协作工作,arXiv
《HuaTuo: Tuning LLaMA Model with Chinese Medical Knowledge》,哈工大开源的医疗智能问诊大模型,基于LLaMA,arXiv
《StructGPT: A General Framework for Large Language Model to Reason over Structured Data》,LLM对结构化数据进行推理,arXiv
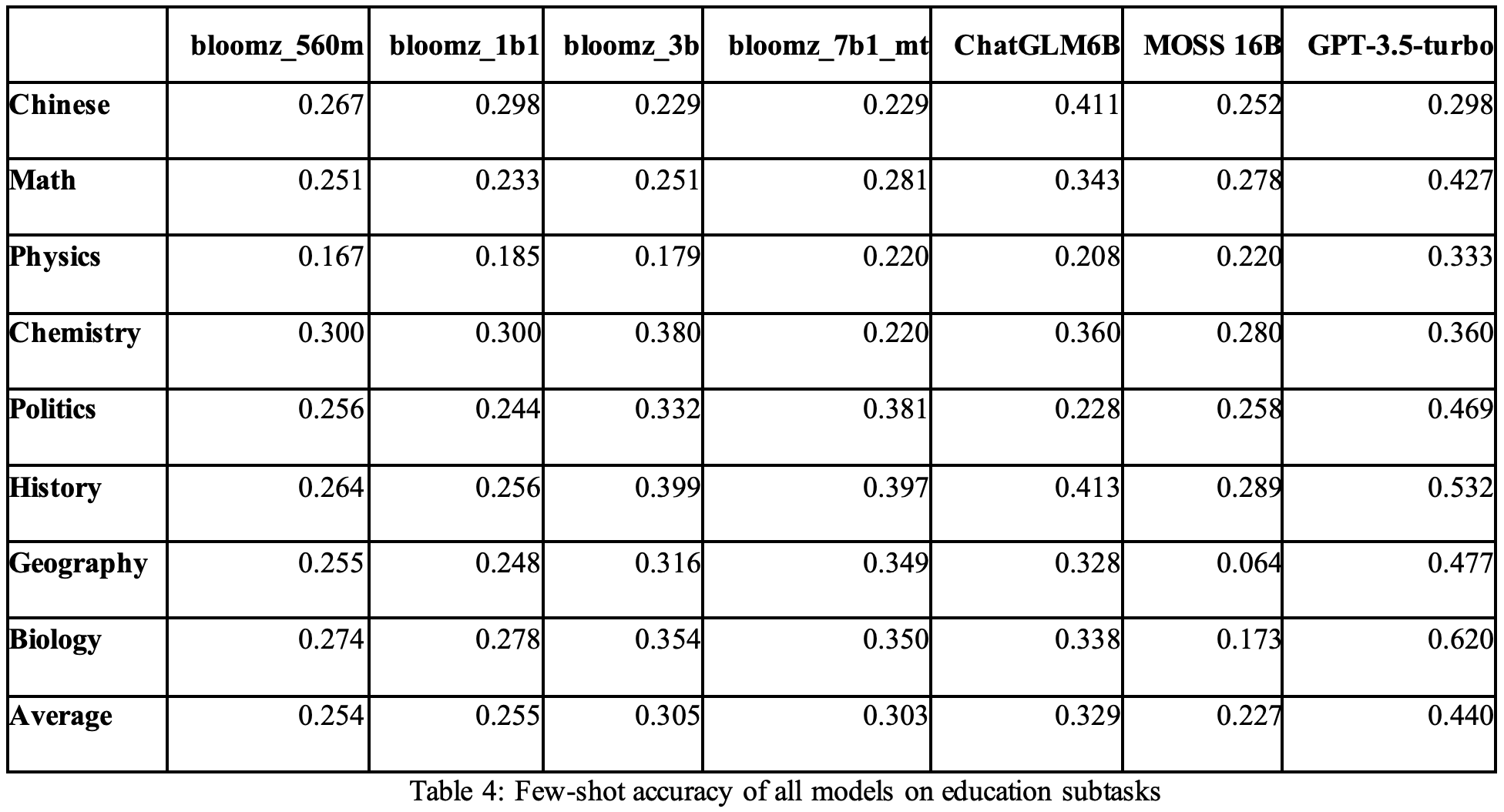
《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》,Princeton与Google Deepmind联合发布的LLM推理工作——思维树(ToT),arXiv
![]()
《Fine-Tuning Language Models with Just Forward Passes》,苏神推荐,”少样本时可以用零阶梯度对大模型微调,只需要跟推理一样的显存”,arXiv,苏神关于零阶梯度的博客
《Large Language Models as Tool Makers》,LLM自动生成用以辅助自己处理新问题的工具,arXiv
《Sparks of Artificial General Intelligence: Early experiments with GPT-4》,微软对GPT-4的分析长文,arXiv
《Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling》,Pythia模型架构开源文章,arXiv
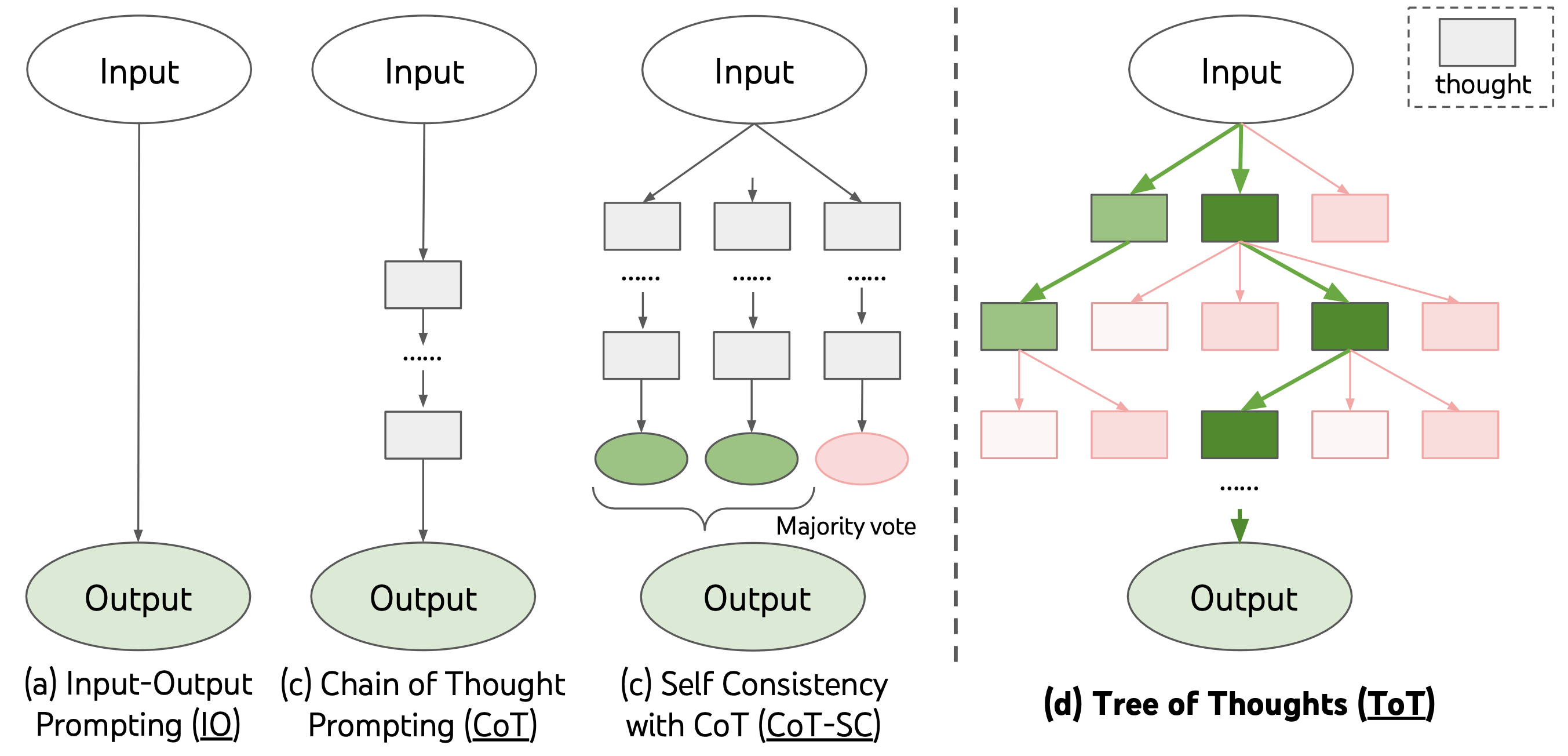
《QLoRA: Efficient Finetuning of Quantized LLMs》,华盛顿大学的新作品,提出一种高效微调方法QLoRA以及一个开源LLM——Guanaco,声称达到ChatGPT效果的99%,arXiv,github
![]()
《Let’s Verify Step by Step》,OpenAI新作,过程监督,极大增强LLM的推理能力并减少幻觉,pdf
![]()
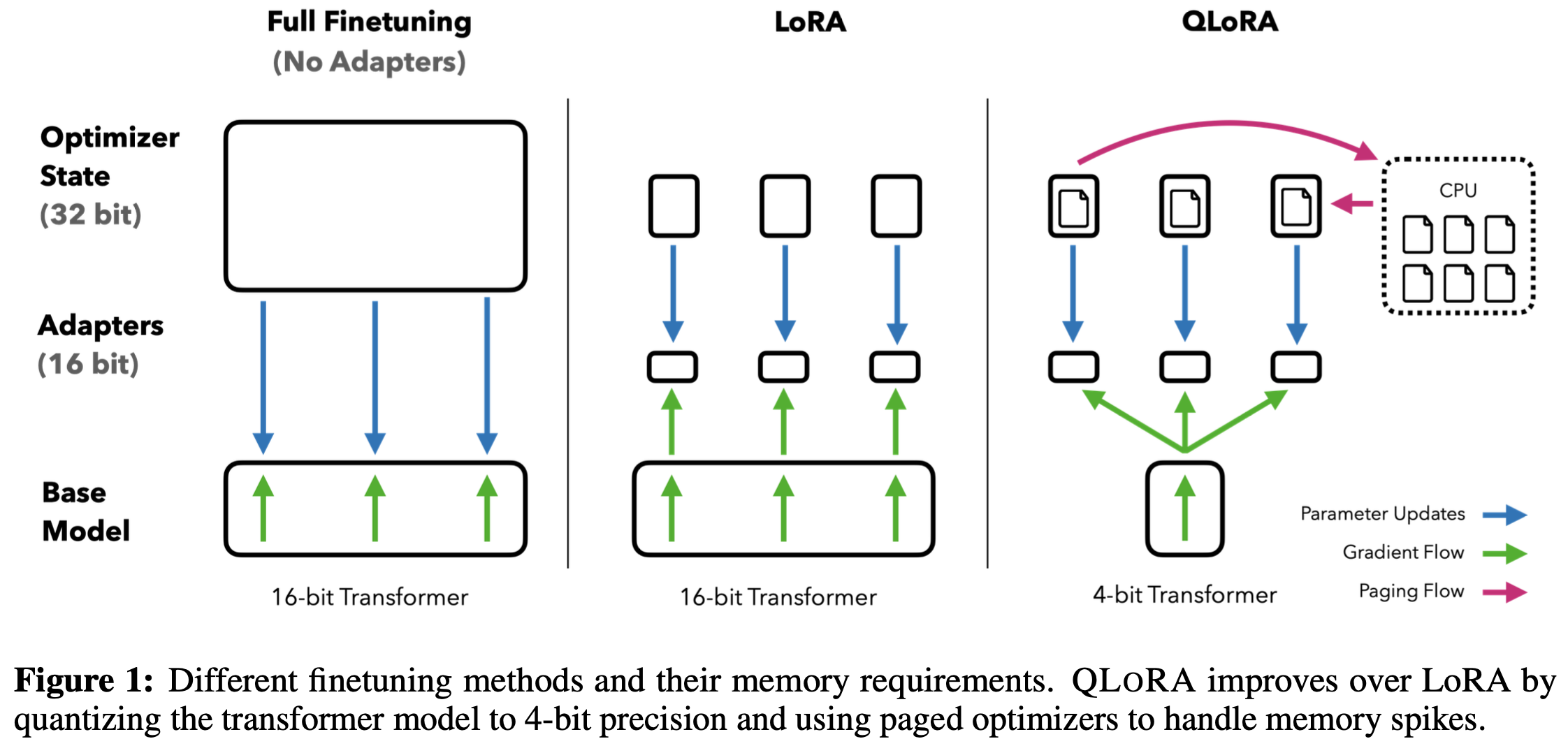
《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》,LoRA,LLM训练的低秩方案,低资源开发的经典技术,arXiv
![]()
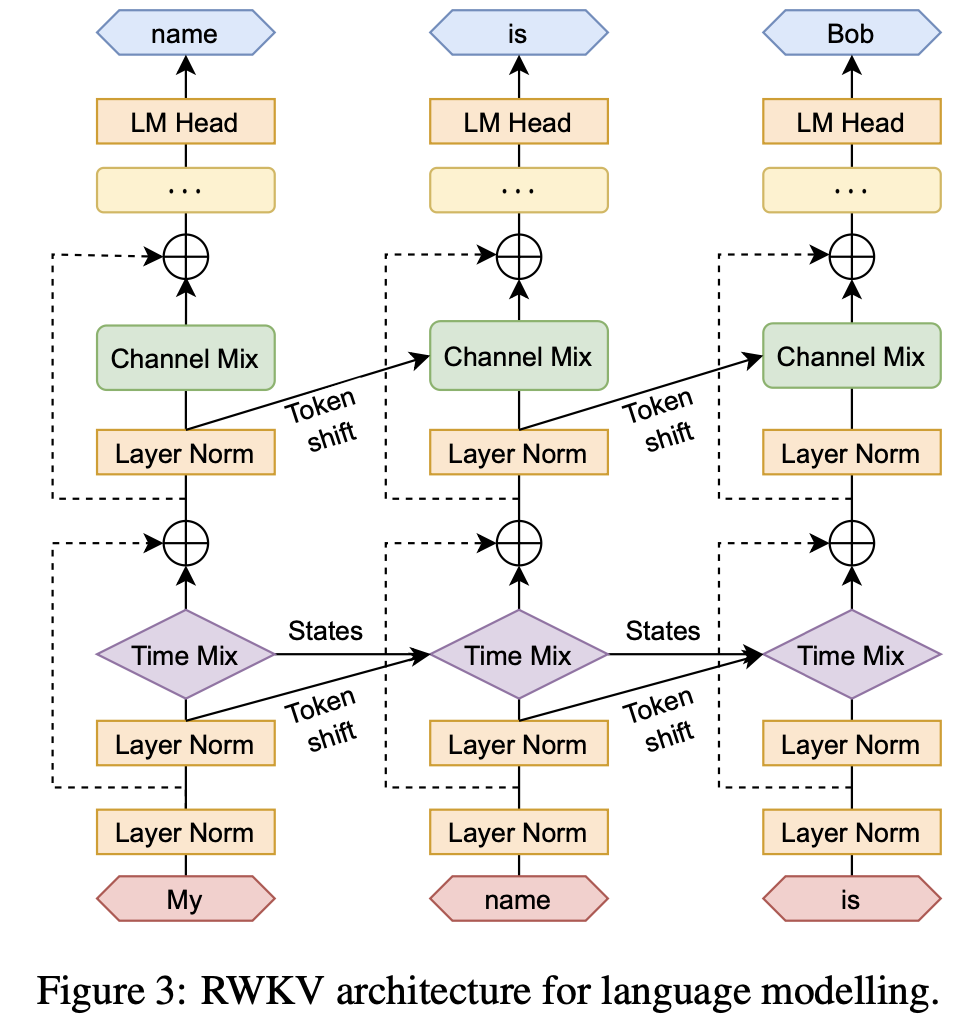
《RWKV:Reinventing RNNs for the Transformer Era》,一个No-Transformer的、基于RNN的LLM方案,arXiv
![]()
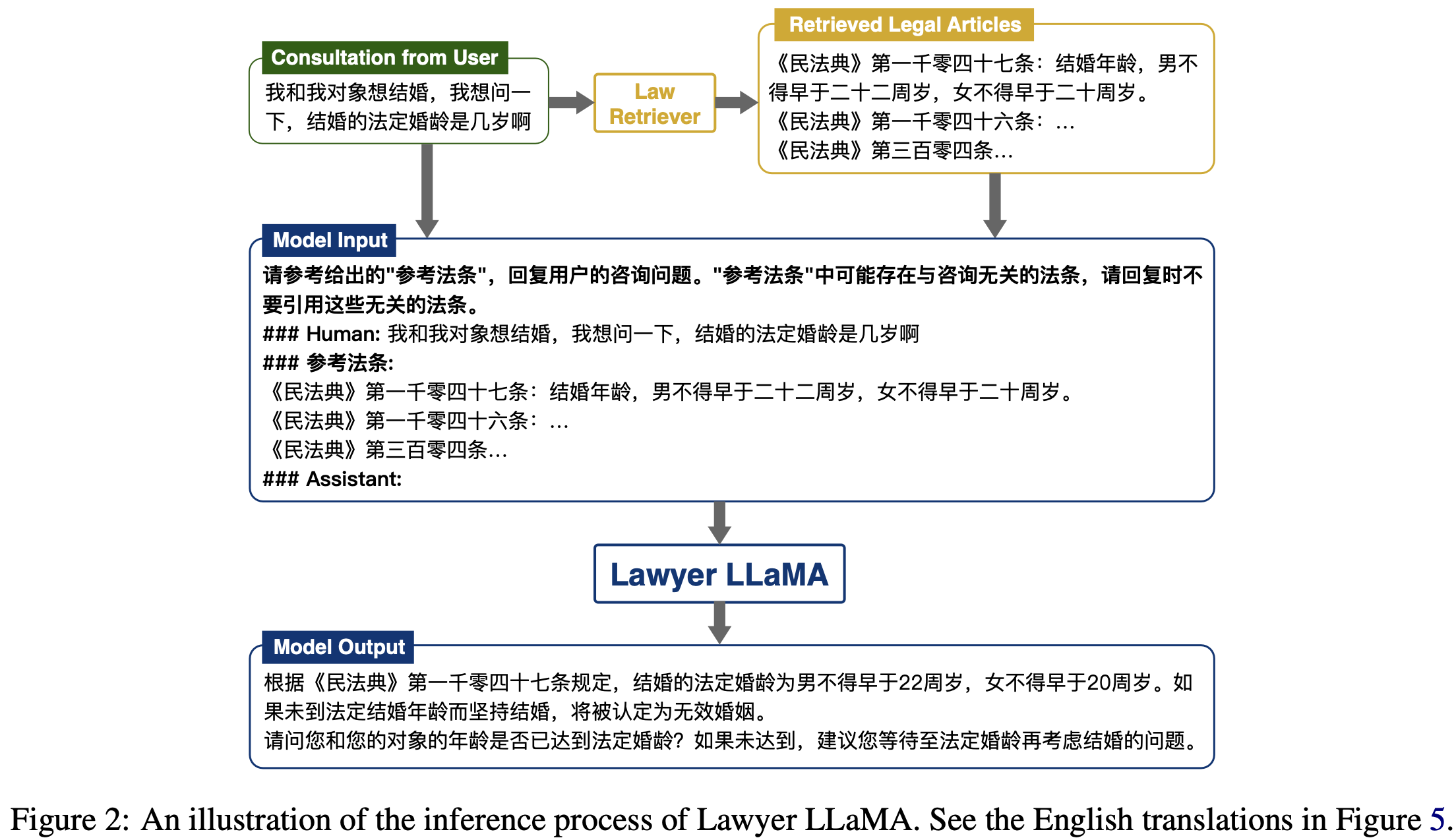
《Lawyer LLaMA Technical Report》,北大的LawAI成果,arXiv
![]()
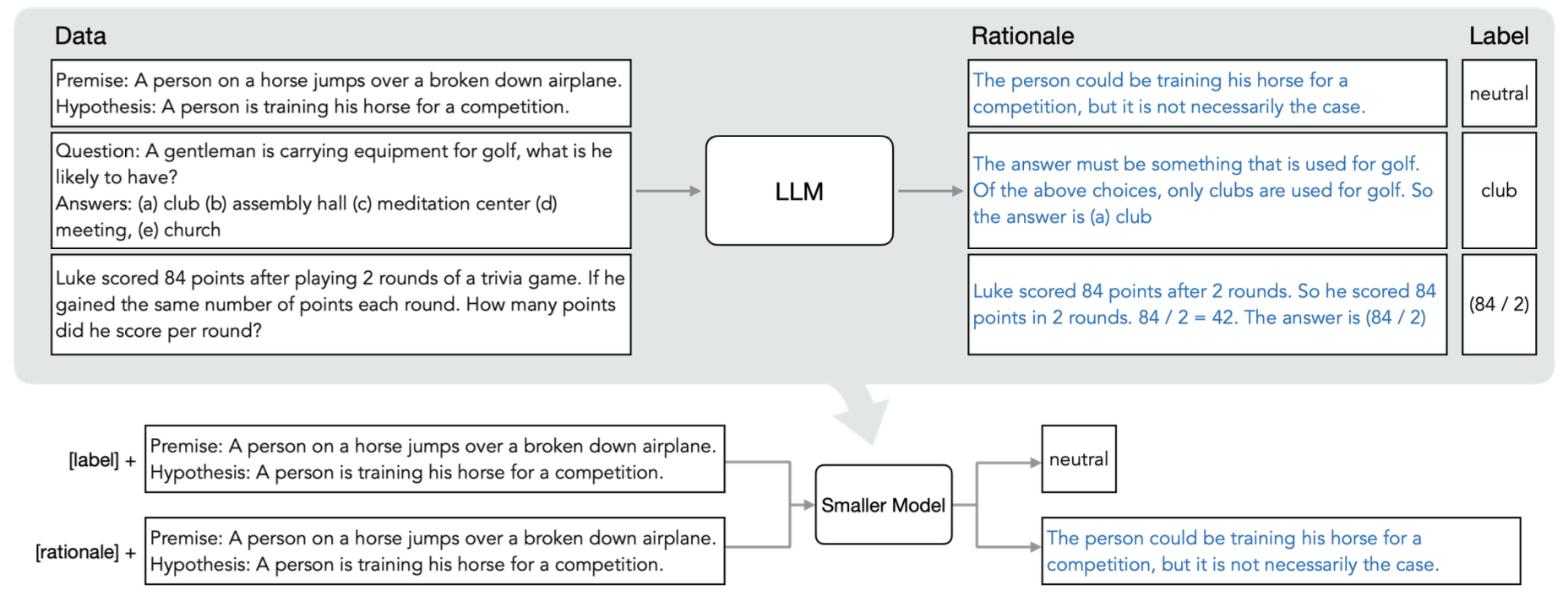
《Distilling Step-by-Step!Outperforming Large Language Models with Less Training Data and Smaller Model Sizes》,华盛顿大学与谷歌共同发表的大模型蒸馏(包括用LLM建数据等工程操作)总结,可以看看是否总结了一些相关理论与Tricks,arXiv
![]()
《Accurate medium-range global weather forecasting with 3D neural networks》,华为发表的被Nature接收的盘古-天气大模型(并非单独的语言模型),Nature
《Lost in the Middle: How Language Models Use Long Contexts》,斯坦福、伯克利联合发表的关于LLM较长输入(长文本、多轮对话)存在的信息缺失问题的研究,可能作为Prompt Engineering带来一定的指导,arXiv
《Copy Is All You Need》,arXiv
《Retentive Network: A Successor to Transformer for Large Language Models》,微软+清华发表的基础模型,目标取代Transformer,arXiv
《InstructEval: Systematic Evaluation of Instruction Selection Methods》,普林斯顿发布的prompt评估方式,arXiv
《ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation》,贝壳发布的训练垂直领域LLM时所遇到的问题及探讨,arXiv
![]()
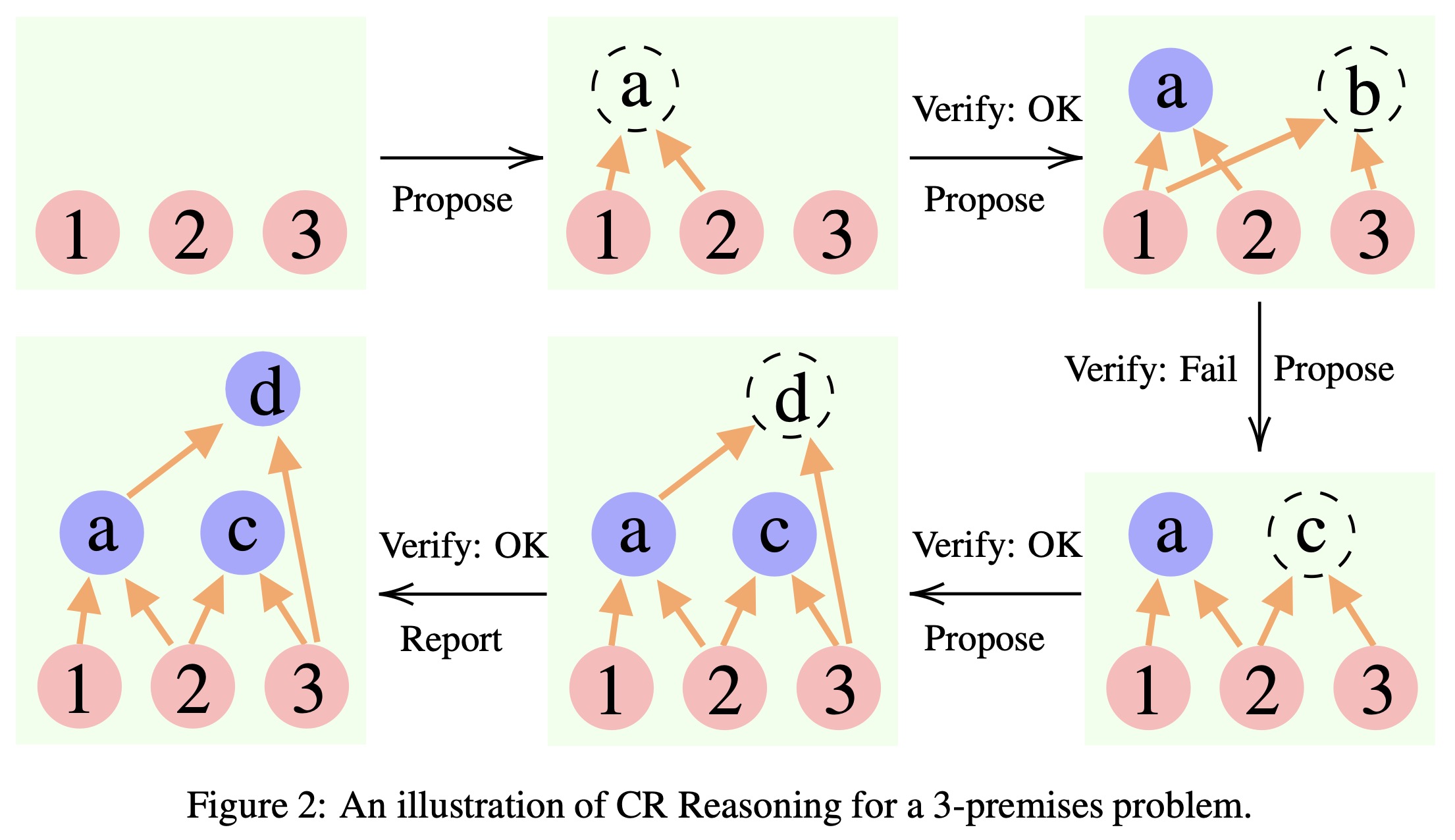
《Cumulative Reasoning With Large Language Models》,提出一种名为“累积推理”的逻辑推理机制,姚期智团队成果,arXiv
![]()
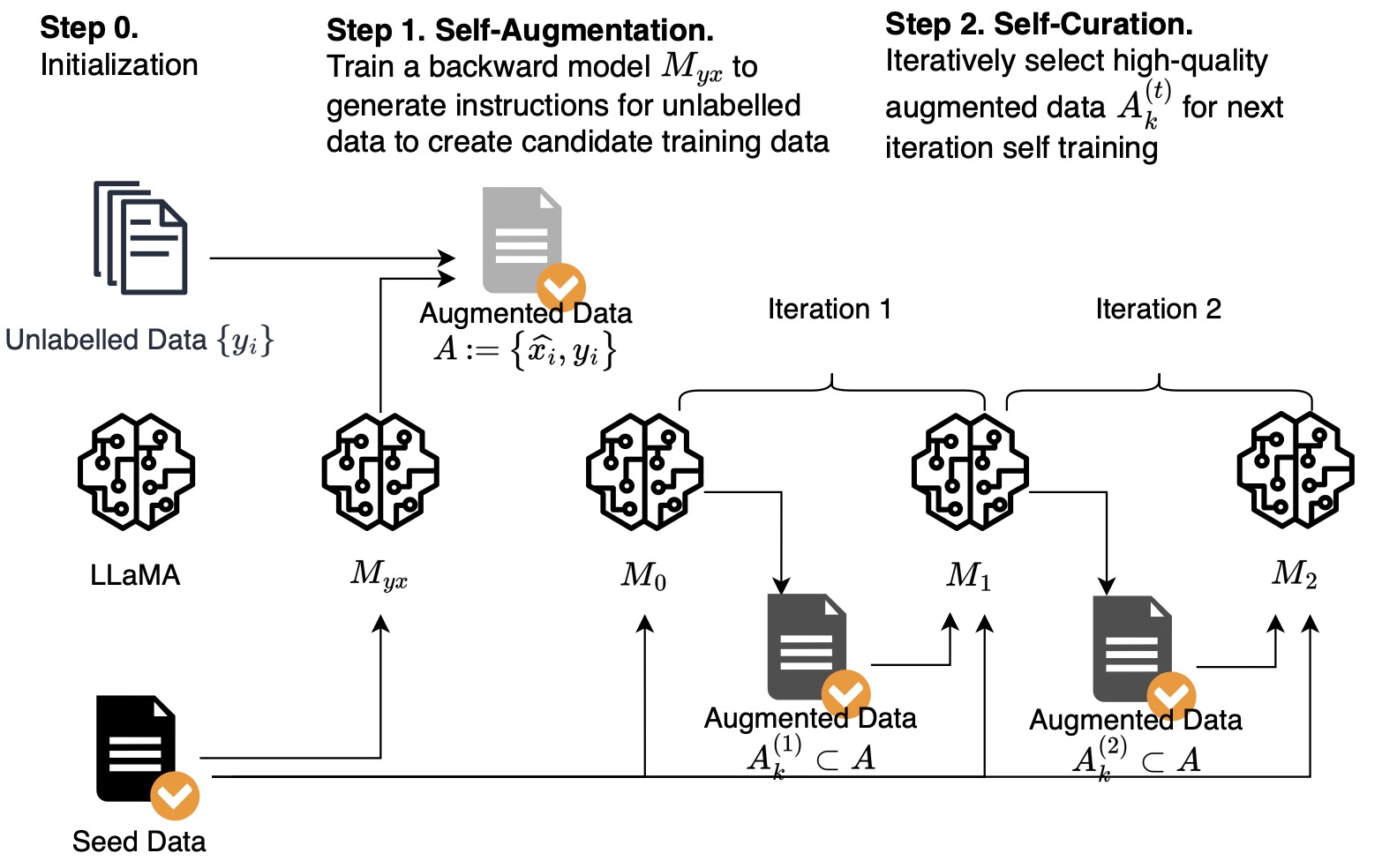
《Self-Alignment with Instruction Backtranslation》,Meta提出的一种通过自动注释相应的指令来构建高质量的指令跟随语言模型的方法,arXiv,zhihu
![]()
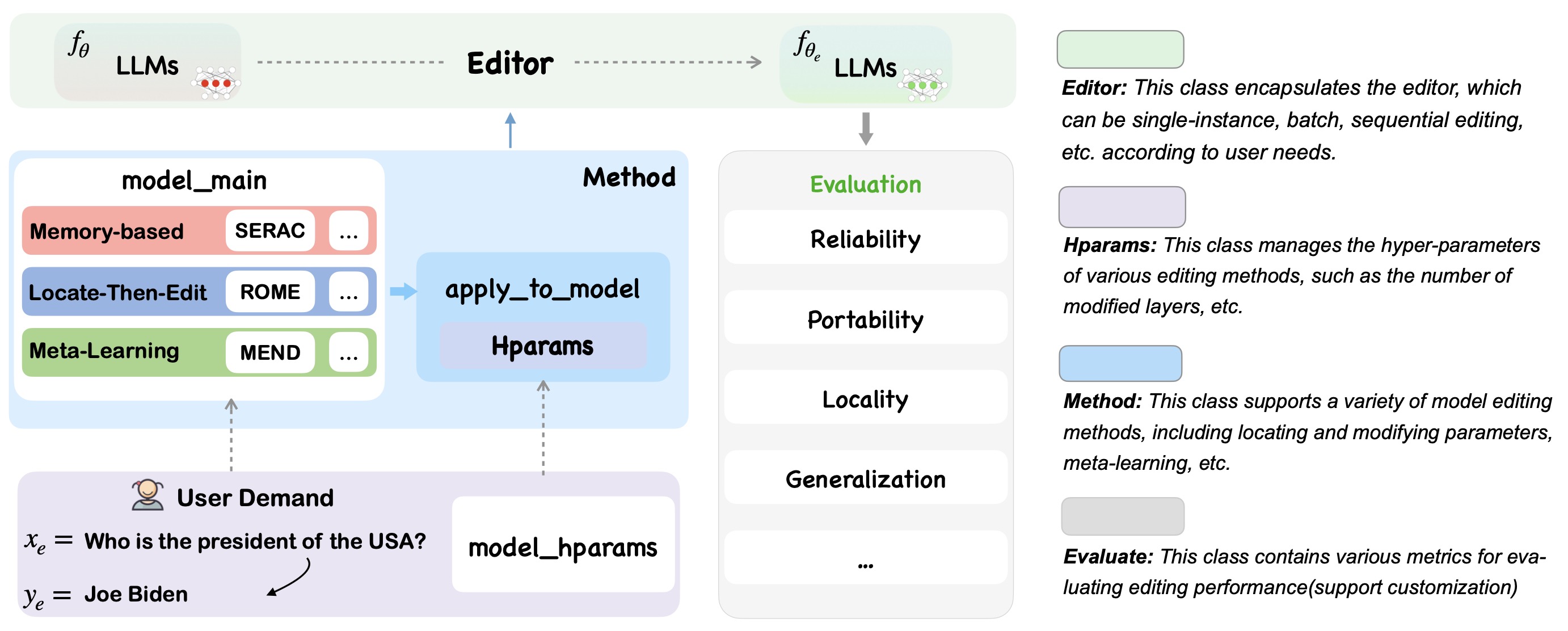
《EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models》,浙大提出的一种知识编辑方案,arXiv,github
![]()
《Informed Named Entity Recognition Decoding for Generative Language Models》,一种用LLM做NER任务的方案,从效果上看,并未比BERT系好多少,但是可以作为实现
one model to rule them all目标的预研项目,arXiv《Consciousness in Artificial Intelligence: Insights from the Science of Consciousness》,Yoshua Bengio等19人联合团队发表的关于AI与意识的探讨,arXiv
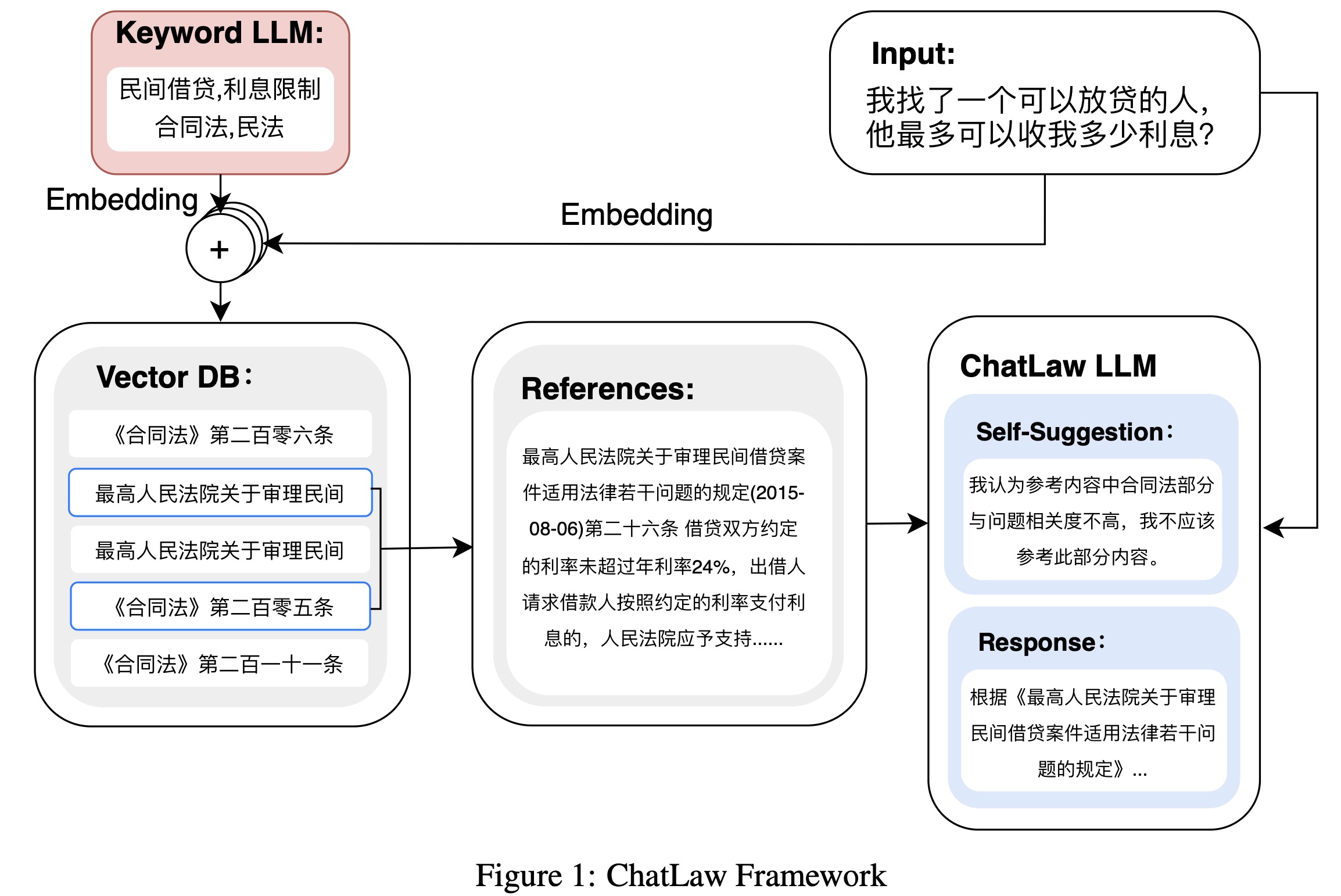
《ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases》,北大深研院发布的ChatLaw法律大模型,github,arXiv
![]()
《Nougat: Neural Optical Understanding for Academic Documents》,META新发布的多模态文档理解工作,可能作为新的OCR工具引入到数据处理工作中,arXiv
Baichuan2技术报告,pdf《The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”》,用”A is B”训练LLM时,LLM不能学会”B is A”,pdf,github
![]()
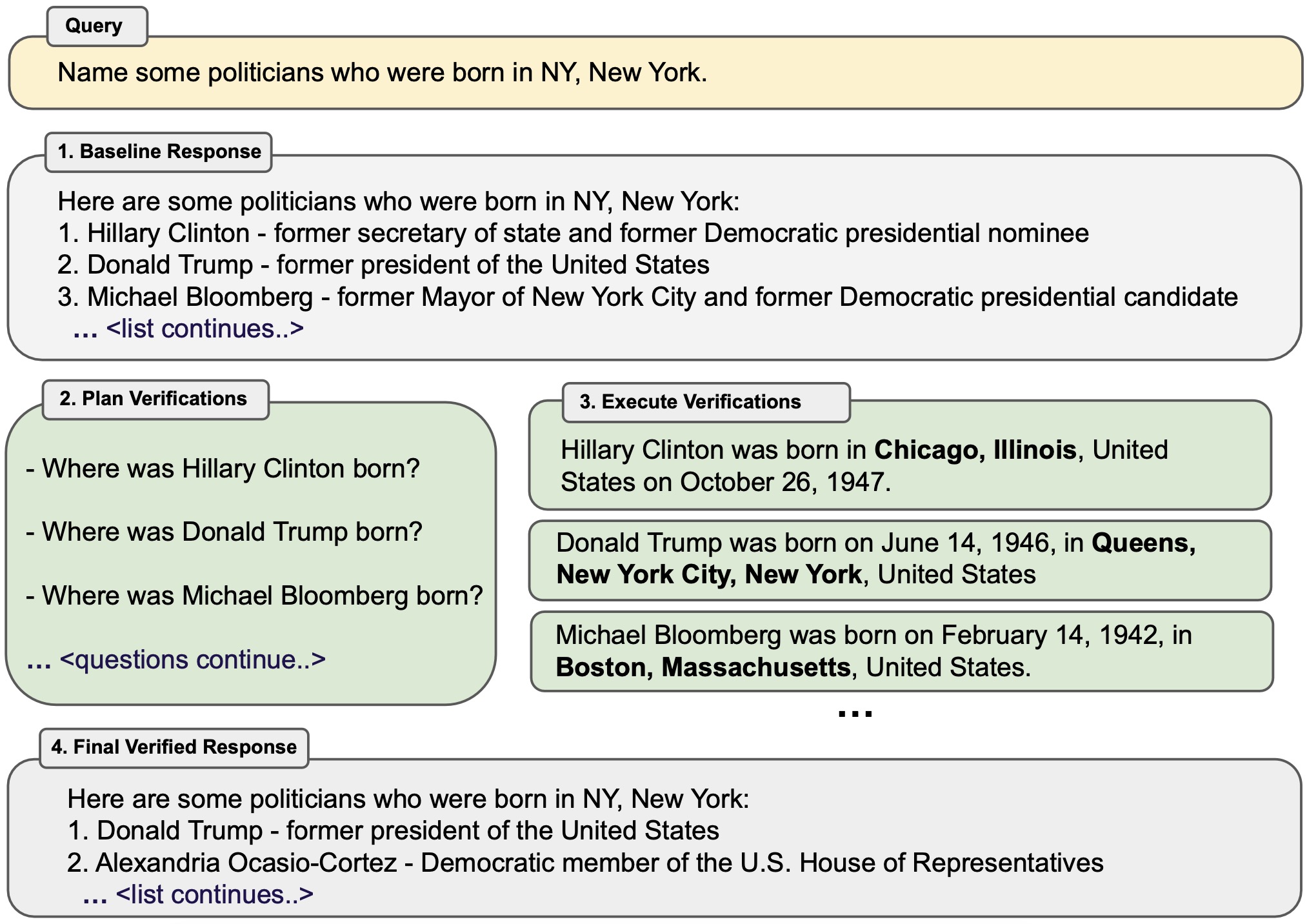
《Chain-of-Verification Reduces Hallucination in Large Language Models》,META提出“验证链”,用于处理幻觉问题,arXiv
![]()
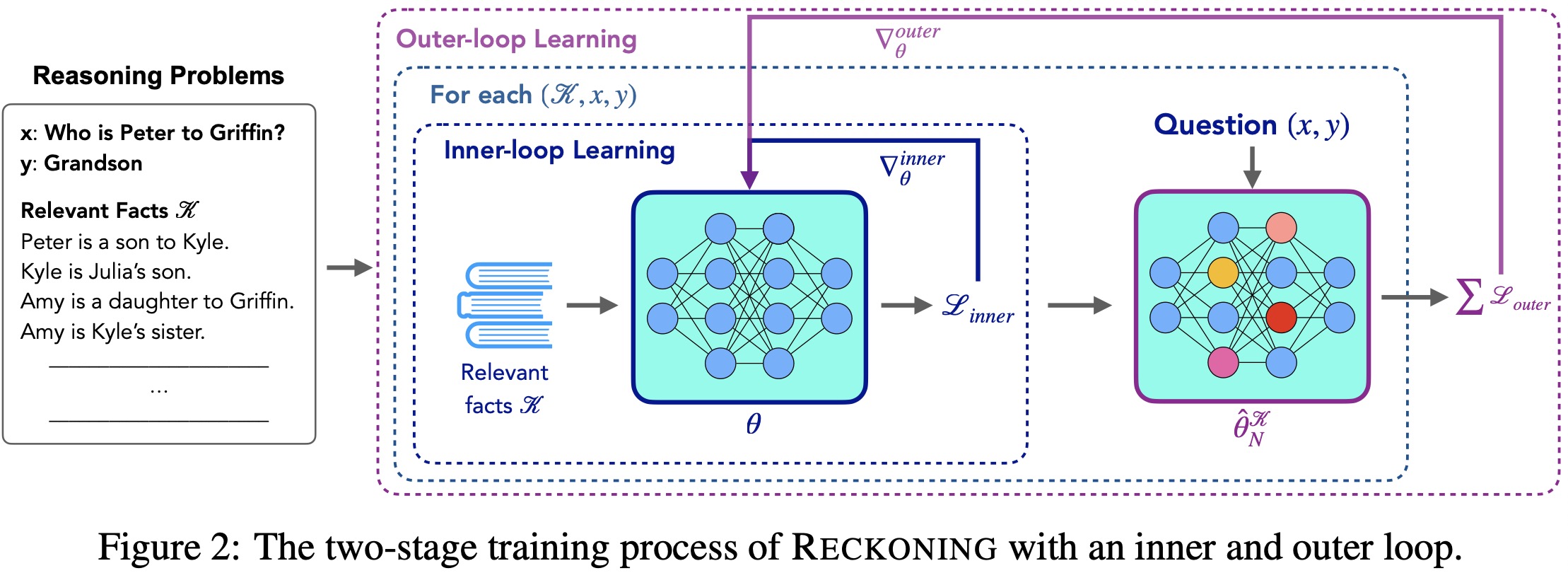
《RECKONING: Reasoning through Dynamic Knowledge Encoding》,洛桑联邦理工学院、斯坦福、META共同发表,一种模型层面“教导”模型使用知识的方法,arXiv
![]()
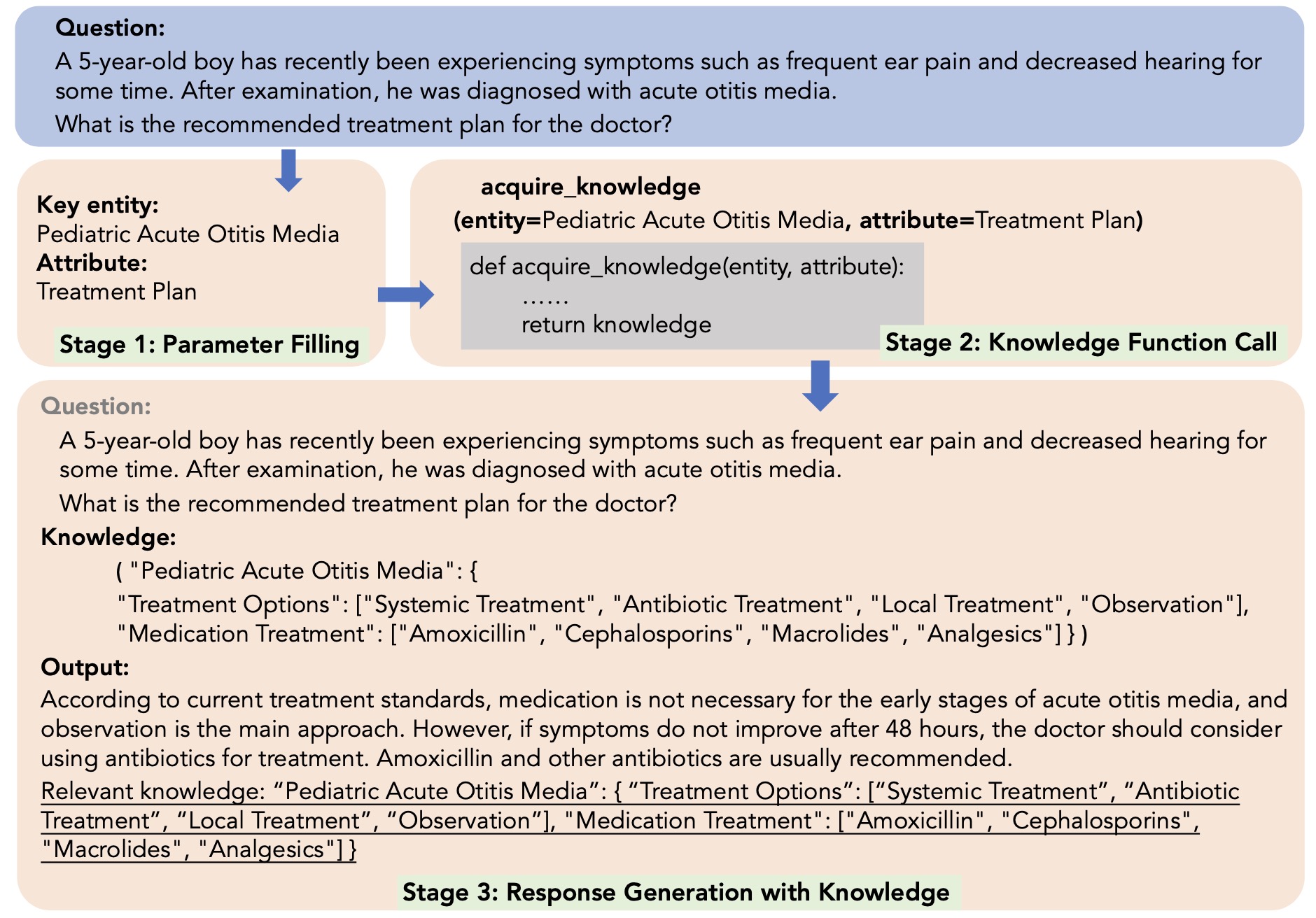
《Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese》,哈工大发布的《基于知识微调的大语言模型可靠中文医学回复生成方法》,arXiv
![]()
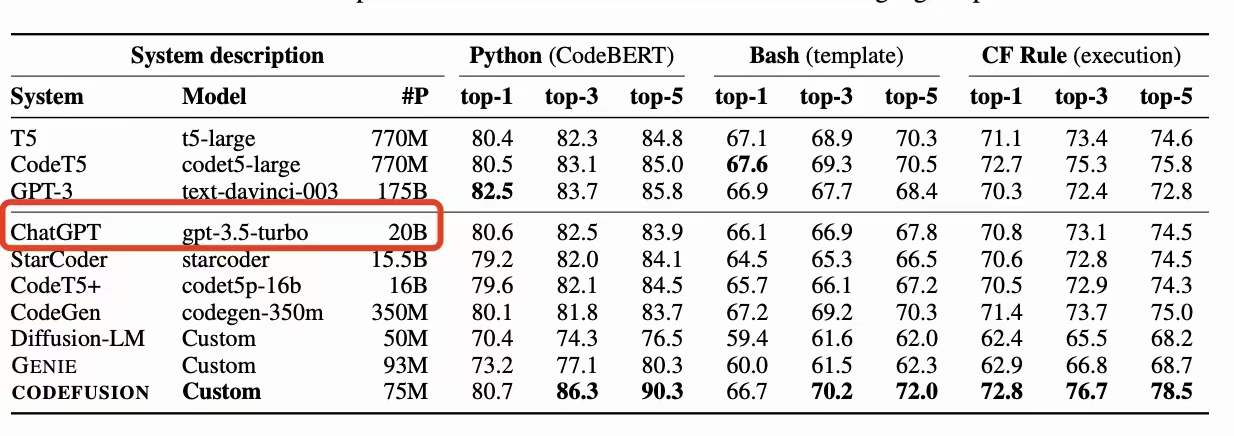
《CODEFUSION: A Pre-trained Diffusion Model for Code Generation》,微软透露chatGPT为20B规模的paper,arXiv
![]()
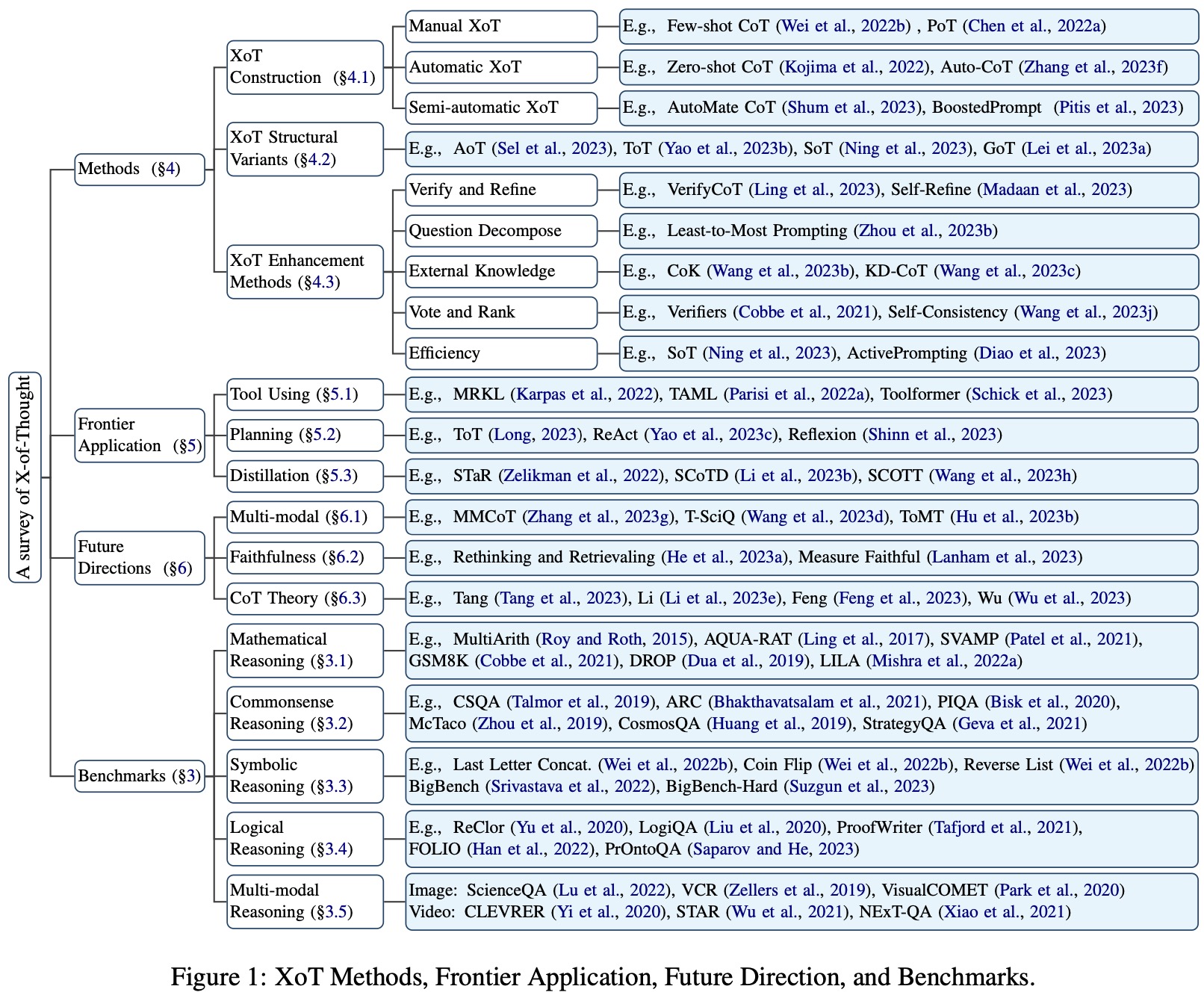
《A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future》,哈工大发布的思维链(CoT)综述,arXiv,github
![]()
《Are Large Language Models All You Need for Task-Oriented Dialogue?》,讨论了LLM在任务型对话中的作用,arXiv
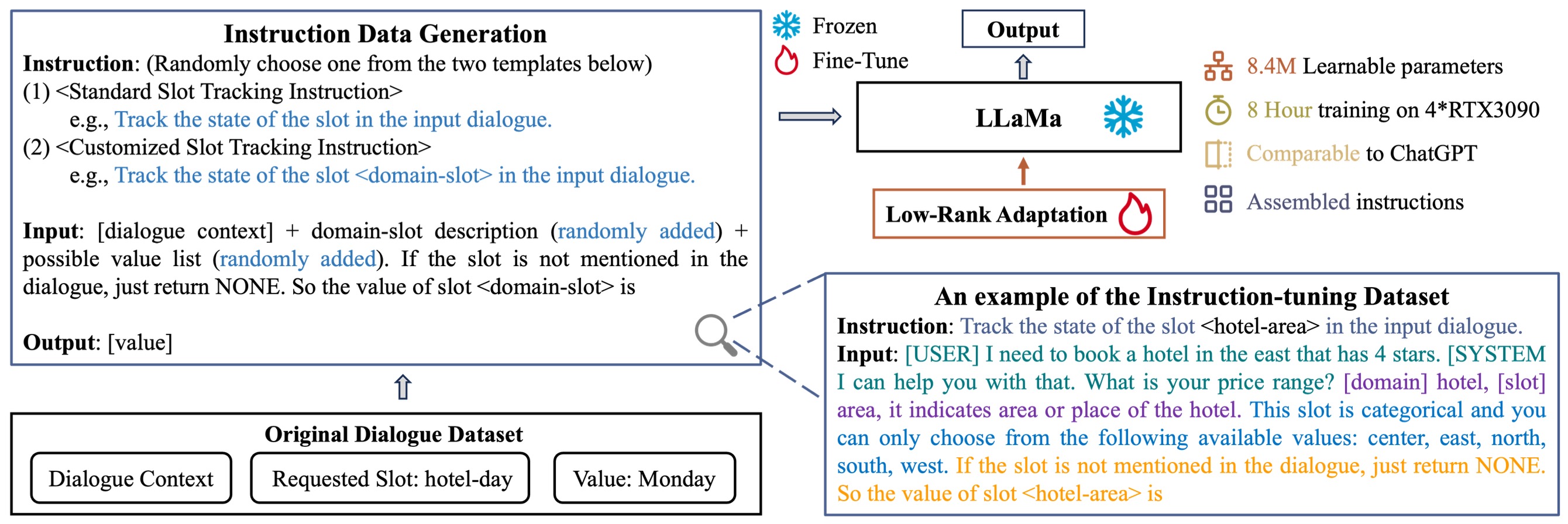
《Towards LLM-driven Dialogue State Tracking》,港理工发表在EMNLP2023上的工作,提出一种适合LLM的DST方法(LDST),arXiv,github
![]()
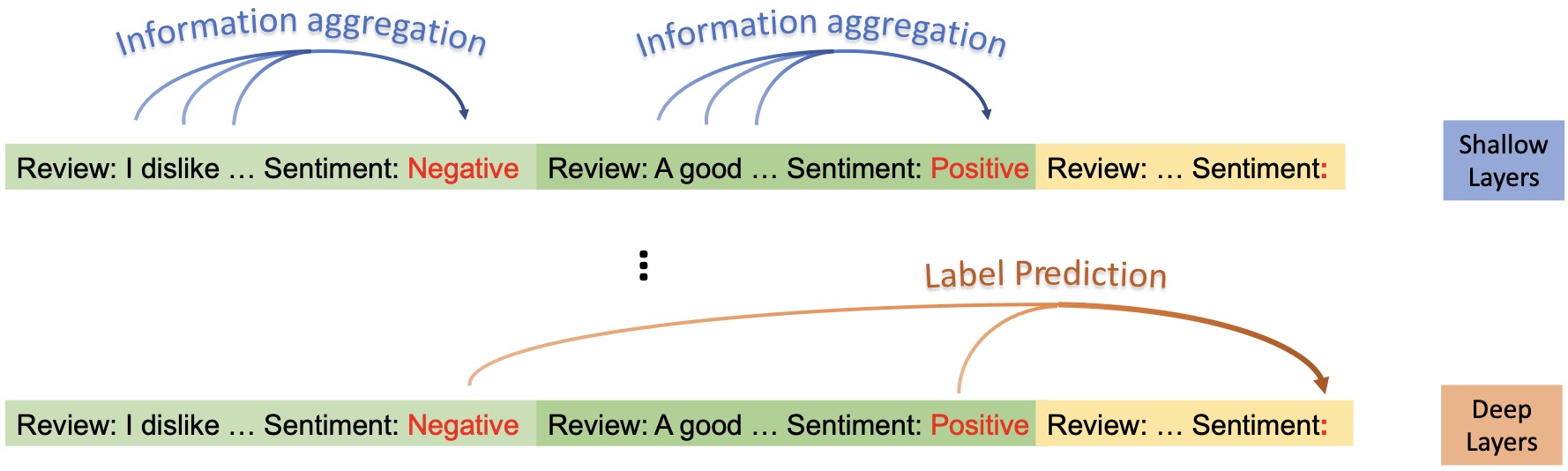
《Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning》,EMNLP2023上北大与腾讯联合发表的对ICL机制原理的研究工作,发现锚点词(Label Words)起到很大作用,pdf,github
![]()
《Large Language Models with Retrieval-Augmented Generation for Zero-Shot Disease Phenotyping》,NeurIPS2023上一篇LLM垂域应用paper,arXiv
《Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs》,微软对FT和RAG的对比工作,arXiv
《DELUCIONQA: Detecting Hallucinations in Domain-specific Question Answering》,EMNLP2023上一篇对垂域LLM幻觉的研究工作,arXiv
《Data Management For Large Language Models: A Survey》,北大与华为诺亚方舟实验室联合发布的LLM数据管理综述,arXiv
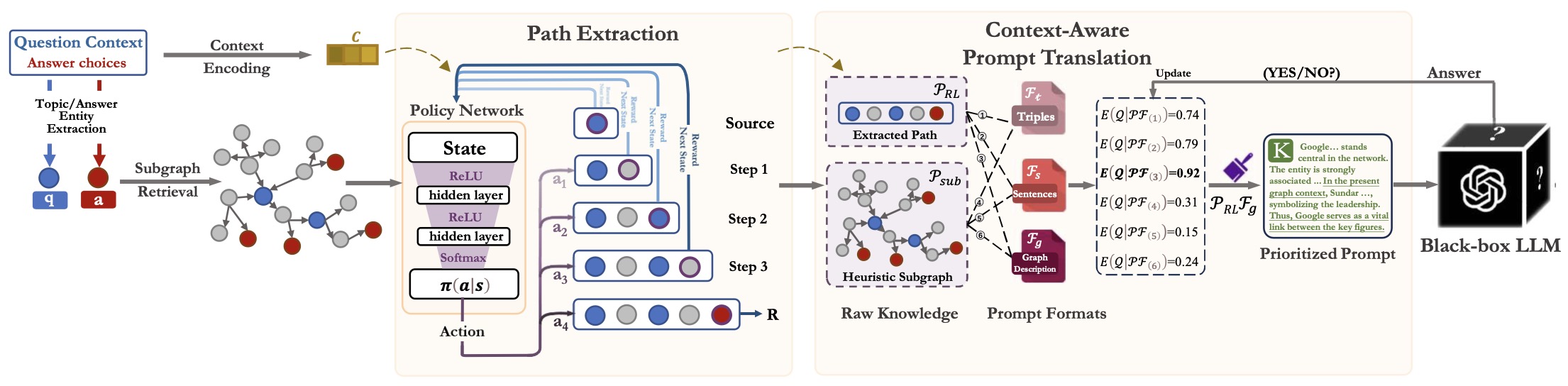
《KnowGPT: Black-Box Knowledge Injection for Large Language Models》,香港理工提出的LLM + 知识图谱方案,值得借鉴,arXiv
![]()
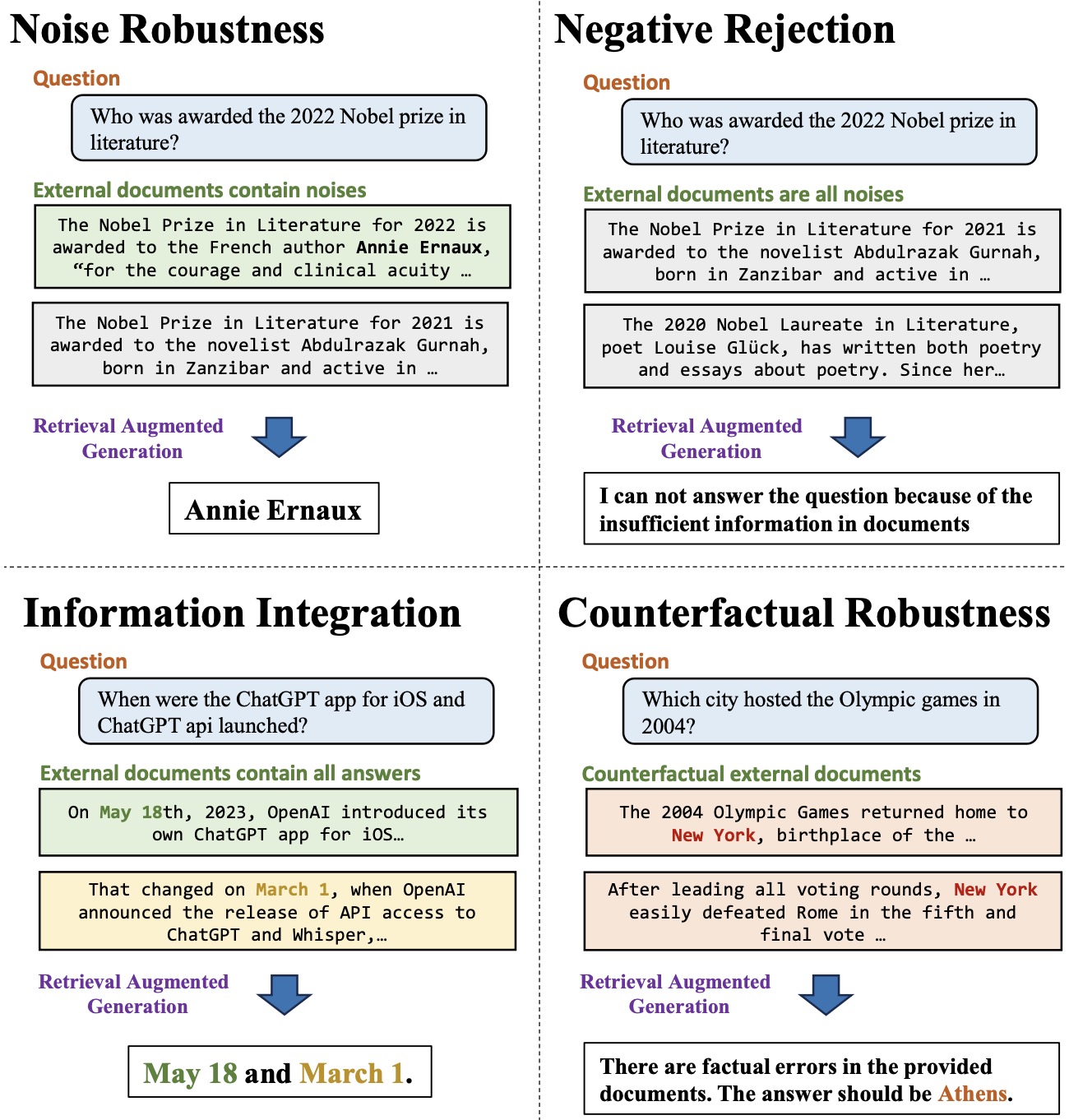
《Benchmarking Large Language Models in Retrieval-Augmented Generation》,RAG减少LLM幻觉的一个benchmark,arXiv
![]()
《Generative Agents: Interactive Simulacra of Human Behavior》,Stanford与Google联合提出的一种生成式Agent构建方案,arXiv
《The Rise and Potential of Large Language Model Based Agents: A Survey》,复旦与米哈游联合发布的Agent综述,arXiv
《Retrieval-Augmented Generation for Large Language Models: A Survey》,同济与复旦发表的RAG综述,arXiv
《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》,DPO,arXiv
《LESS: Selecting Influential Data for Targeted Instruction Tuning》,陈丹琦团队的Less Is More工作,arXiv
《Repetition Improves Language Model Embeddings》,CMU提出的Echo Embedding,通过重复拼接句子用于LLM推理,获得该句子的embedding,arXiv
《Corrective Retrieval Augmented Generation》,2024年2月中科大与Google联合提出的RAG(CRAG)方案,在原本的RAG基础上,增加了一个做简单的知识正确性决策和纠正的中间模块,arXiv
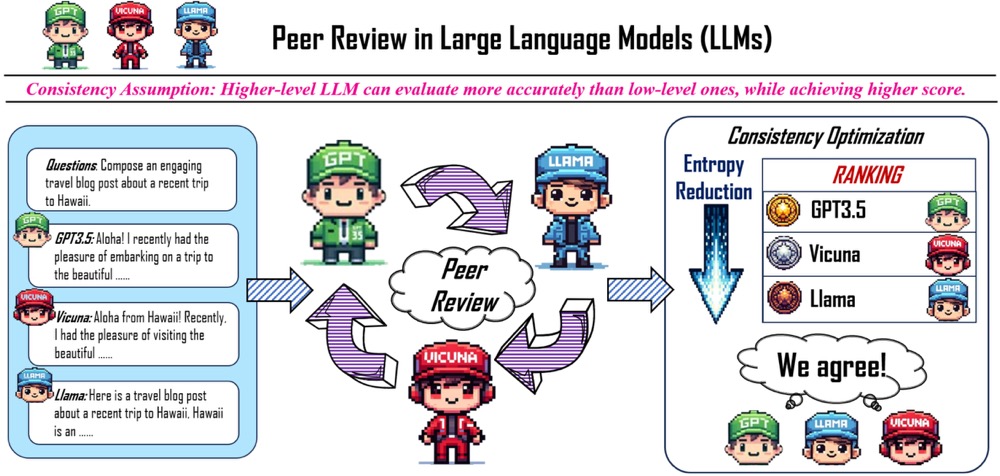
《Peer-review-in-LLMs: Automatic Evaluation Method for LLMs in Open-environment》,北大深研院提出的LLM评估方案,arXiv
![]()
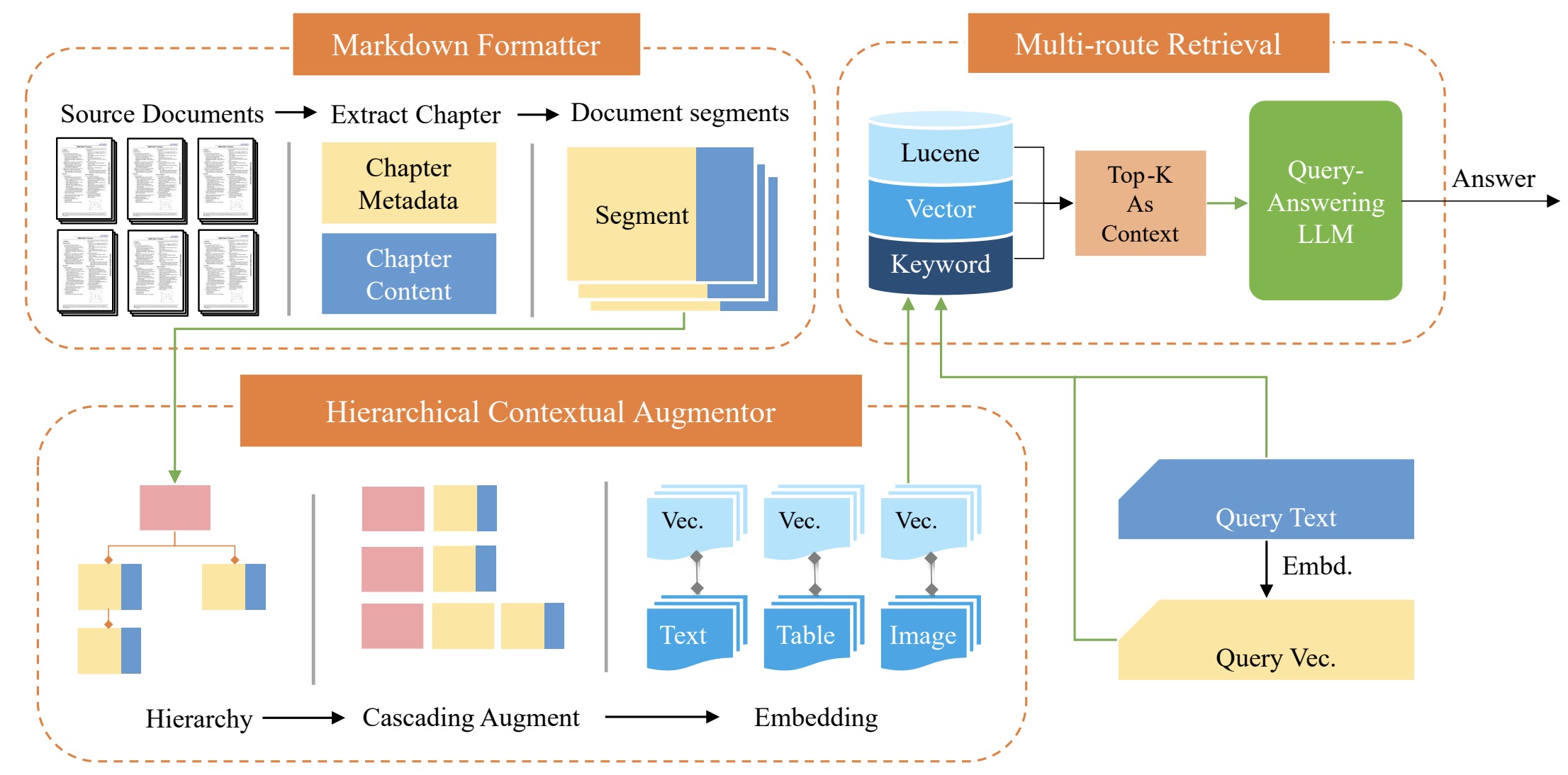
《HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA》,南航提出的多文档QA(RAG)方案,arXiv,github
![]()
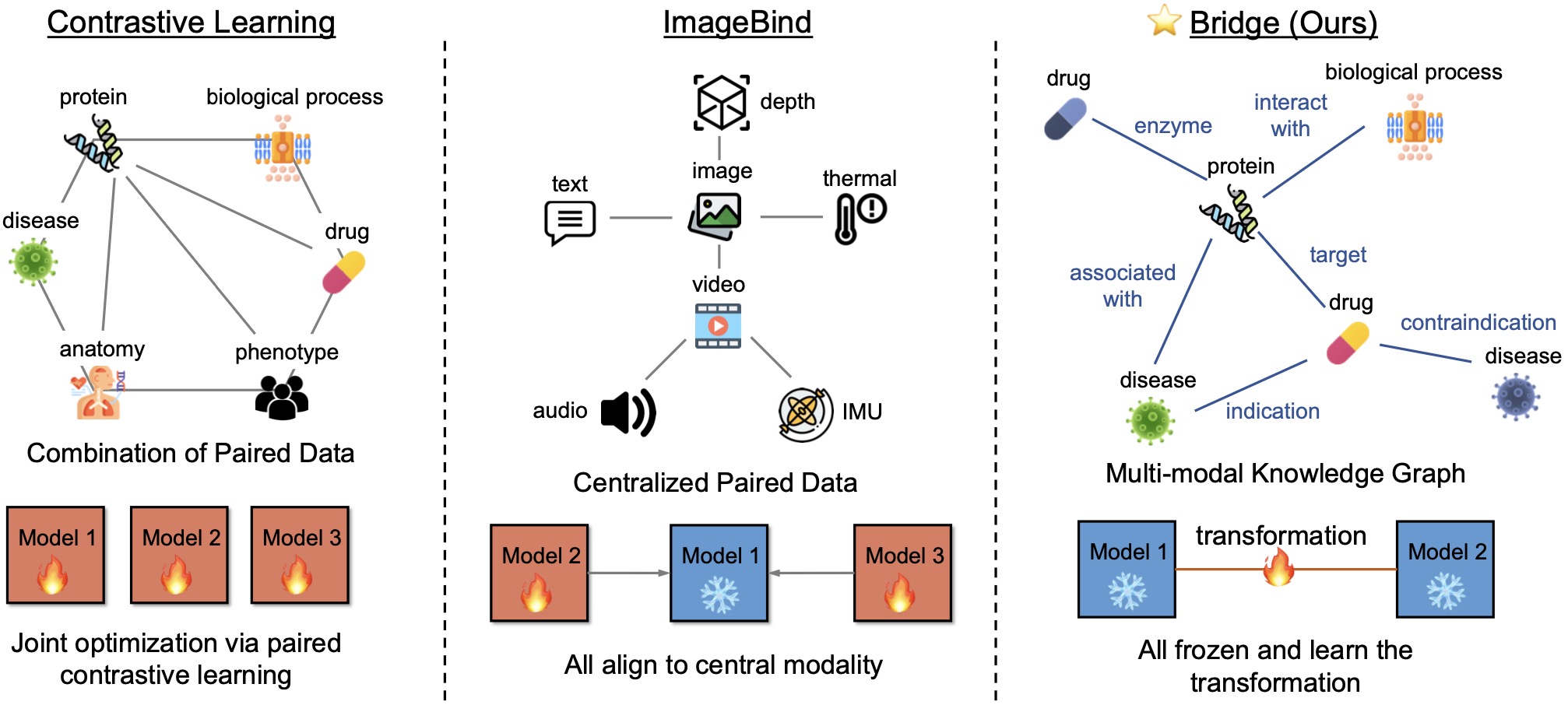
《BioBRIDGE: Bridging Biomedical Foundation Models via Knowledge Graphs》,UIUC发表在ICLR2024上的工作,利用知识图谱连接多个单模态模型,实现多模态,arXiv,github
![]()
《Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering》,Linkedin发表的RAG+知识图谱应用方案,arXiv
![]()
《LANGUAGE MODELING IS COMPRESSION》,“压缩即智能”,arXiv
《Reverse Thinking Makes LLMs Stronger Reasoners》,2023的《The Reversal Curse》一文阐述的LLM缺陷似乎也能使用本文提出的方法进行处理。数据增强方案 + 对训练任务的优化思路使得这一方案更make sense了,利好模型推理与幻觉问题的处理,值得一试。arXiv
《S-LORA: SERVING THOUSANDS OF CONCURRENT LORA ADAPTERS》,Berkeley、Stanford、上海交大联合发布的工作, 针对LLM服务中动态加载LoRA的技术。arXiv, github


4. NL2SQL
《DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction》,NL2SQL最难的数据集(Spider1.0)截止20230505的SOTA,arXiv,github
《A comprehensive evaluation of ChatGPT’s zero-shot Text-to-SQL capability》,2023年清华与Philip Yu团队的ChatGPT + NL2SQL综述,arXiv
《Evaluating the Text-to-SQL Capabilities of Large Language Models》,2022年的一篇LLM + NL2SQL综述,arXiv
《RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL》,人民大学2023年的一篇NL2SQL工作,arXiv
一个研究全参数微调与LoRA微调的效果差异的研究,arXiv
提出BIRD数据集,ChatGPT仅能达到40%准确率(人类为92%),arXiv
Natural SQL(NatSQL),2021年提出的一个SQL与NL的中间衔接方案,arXiv
《How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings》,探讨了在NL2SQL任务下应该如何对LLM编写Prompt的问题,本文对于冷启动阶段的NL2SQL项目具有指导性意义,arXiv
《Exploring Chain-of-Thought Style Prompting for Text-to-SQL》,探讨了如何编写适用于NL2SQL任务的带CoT的Prompt,arXiv
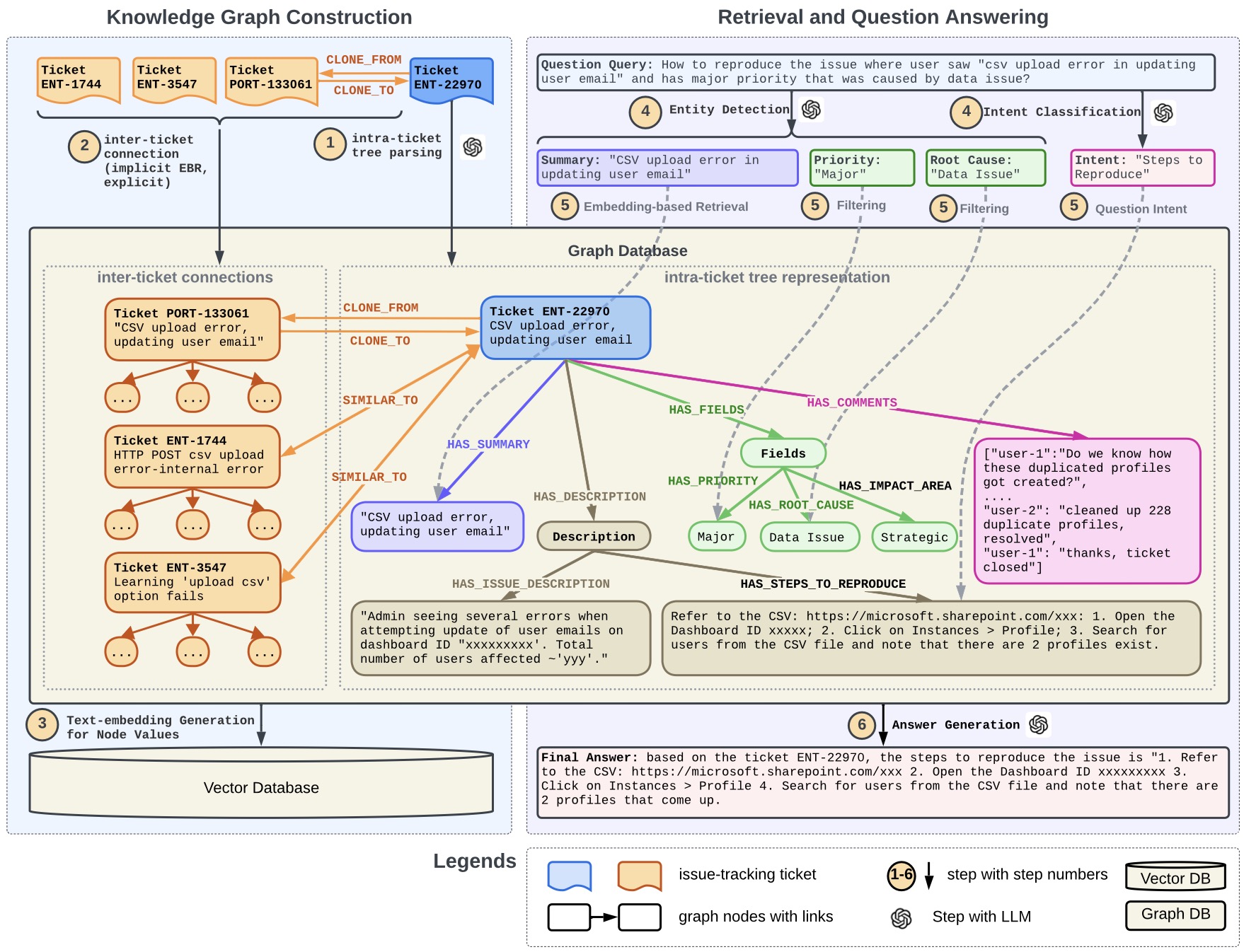
《Text2Analysis: A Benchmark of Table Question Answering with Advanced Data Analysis and Unclear Queries》,发表在AAAI2024上的工作,着重分析了生成文本分析报告的技术(而非仅仅是NL2SQL),arXiv
![]()
《Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect》,密歇根大学与西湖大学联合发表在COLING2022上的Text-to-SQL综述,arXiv
《A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions》,中科大2022年发表的一篇Text-to-SQL综述,arXiv
5. 模型压缩
5.1 模型剪枝
LayerDrop,对每一层进行随机mask,提升模型每一层的鲁棒性,最终可以根据mask概率直接修剪模型,arXiv,知乎
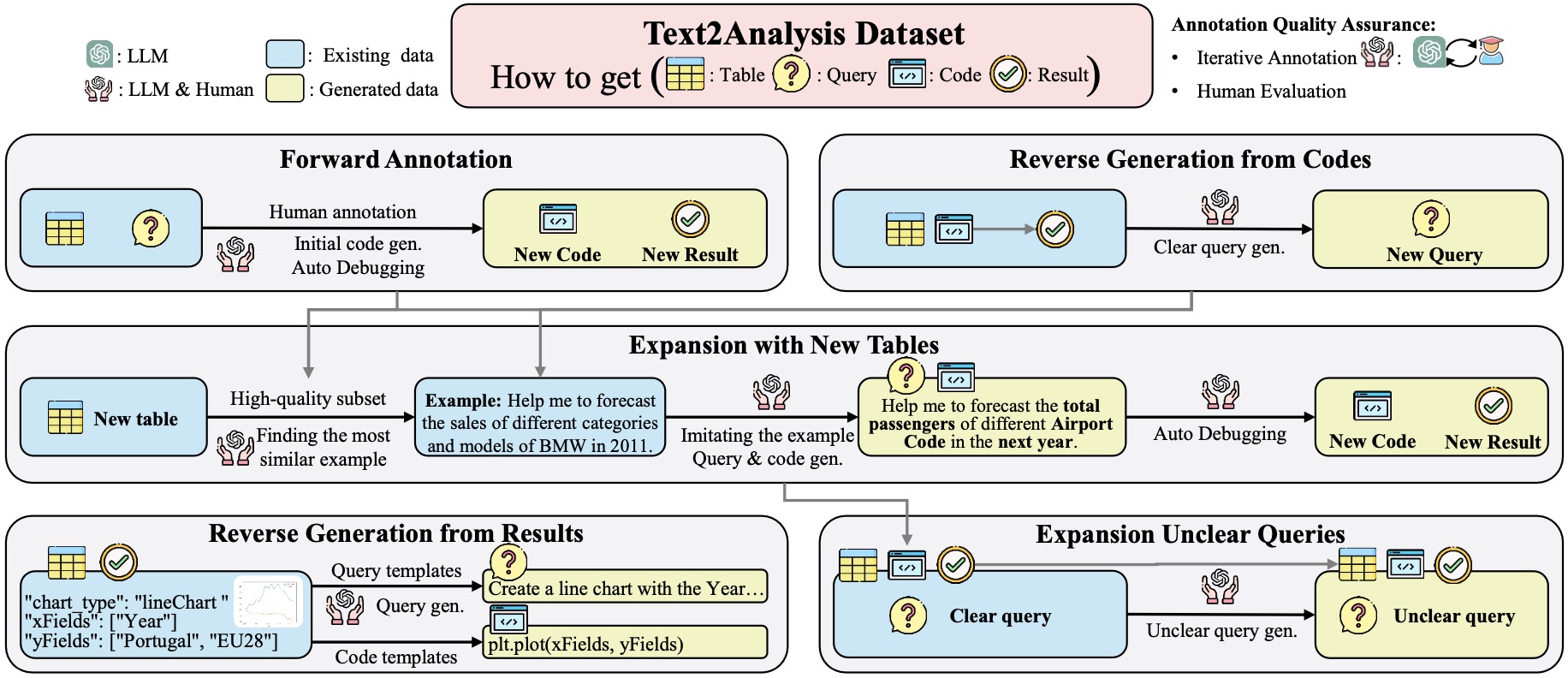
BERT-of-Theseus,利用module-replacing思路对模型进行压缩,无需经过“先训大模型,再压缩成小模型”的耗时过程,苏神博客,知乎:邱震宇
5.2 模型蒸馏
The very beginning of the Model Distillation,《Distilling the Knowledge in a Neural Network》,Geoffrey Hinton,arXiv
MobileBERT,一个移动端的NLP预训练模型,从目前网络上的资源来看,实验结果为在Pixel4上运行只需要40ms,GLUE得分为77.7,比BERT-base低0.6(数据来源: 陈之炎的知乎回答)。现已加入google-research豪华午餐。arXiv,知乎,github
6. Dialogue Management
- 对话管理综述(2021),arXiv
7. 多模态
8. 对比学习
9. ASR
wav2vec2.0,一个强大的语音预训练模型,使用了对比学习模式,github
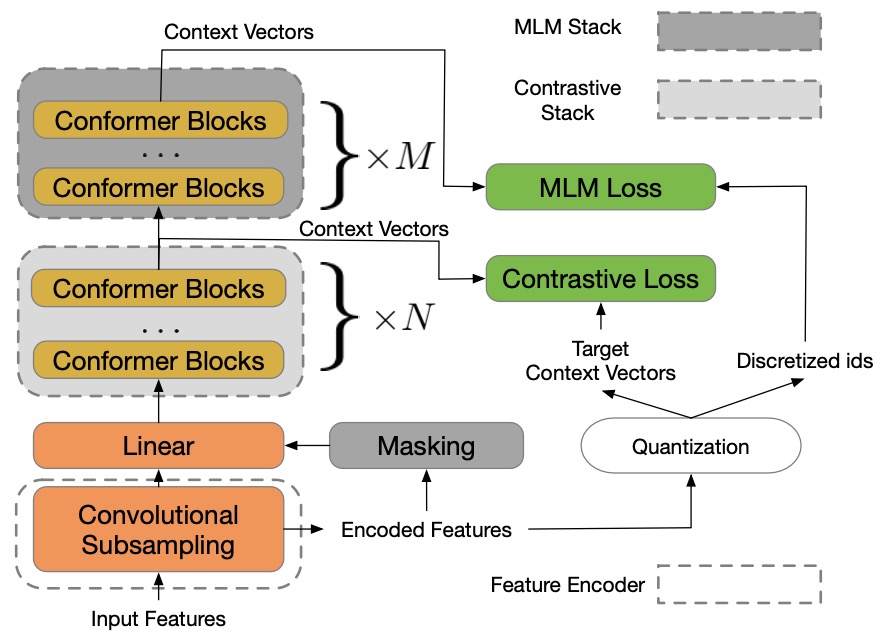
w2v-BERT,目前的SOTA(20220415),结合了wav2vec2与HuBERT,利用MLM增强了wav2vec2的效果,arXiv
![]()
LREC2020上的一篇对NER在语音领域应用与研究现状的探讨,《Where are we in Named Entity Recognition from Speech》,pdf-online
Interspeech2022上的一篇端到端ASR工作,在模型设计时考虑了中文拼音特征。arXiv
![]()
一篇关于CTC的博客,《Sequence Modeling With CTC》
一篇关于CTC Peaky Behavior的研究,《Why dose CTC result in peaky behavior?》,pdf
Interspeech2020的一个通过优化Label Smoothing来处理同音字问题的方案,《Homophone-based Label Smoothing in End-to-End Automatic Speech Recognition》,pdf-online
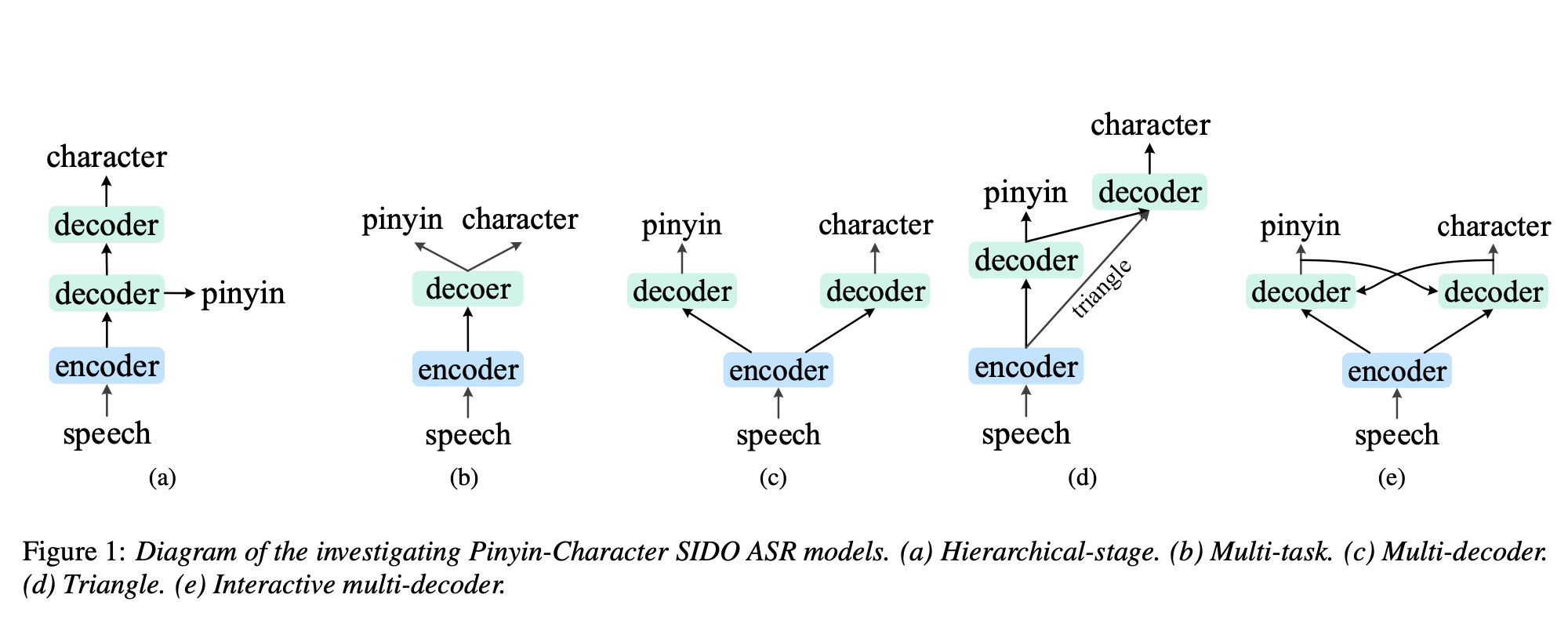
10. SLU: Spoken Language Understanding
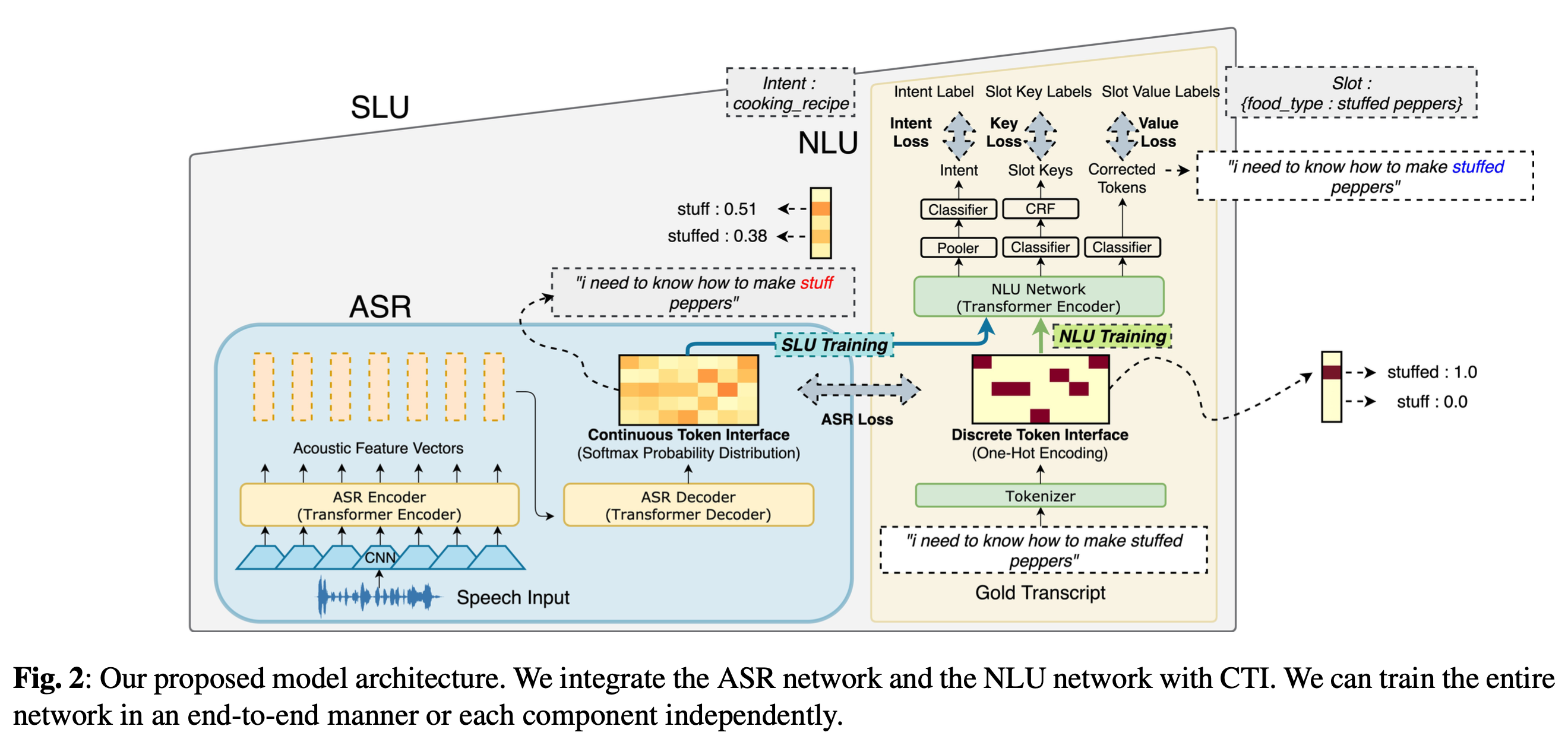
Continuous-Token-Interface(CTI),提出一种结合ASR与NLU任务的联合学习模型,来自ICASSP2022,《Integration of Pre-trained Networks with Continuous Token Interface for End-to-End Spoken Language Understanding》,arXiv
![]()
11. NLP Pre-Train Model
- ELECTRA,一个我早就应该了解的预训练模型,效果与roberta持平,碾压BERT,具有更快的推理速度,arXiv,github(google),github(Chinese-ELECTRA),知乎导读(李rumor)
- PERT,SCIR在2022年3月份新出品的预训练模型,预训练任务为替换词序形成乱序文本后预测原token位置,arXiv,github
12. TTS: Text-To-Speech
- FastSpeech2,arXiv
13. DocumentAI
Donut,ECCV2022上提出的一种不依赖OCR的用于处理文档理解任务的transformer,arXiv,github
13.1 TableStructureRecognition(TSR)
- TSRFormer,利用参考点检测与分割线回归处理变形图像中的表格识别问题,arXiv
*. 其他
LSTM+CRF学习率不一致,苏神博客:你的CRF层学习率可能不够大
《Beyond Words: A Comprehensive Survey of Sentence Representations》,一篇文本表示学习综述,arXiv




