最近chatGPT再一次引发了世人对人工智能领域的广泛关注,可以说是人工智能发展史上的一个新的里程碑。笔者身边行业内外的朋友们都纷纷体验了这一史无前例的对话系统,大家的反馈也都出奇地一致——“太强大了!”是啊,一个能准确理解提问者的意图并给出流畅的答案、能进行知识问答、甚至还能写代码的人工智能产品,谁不喜欢呢?但作为从业者,笔者更关注的是这样的产品究竟会给行业带来哪些影响、使用类似的技术能让我们做到哪些过去做不到的事情。例如笔者所在的法律人工智能(LawAI)赛道那样,在chatGPT的浪潮下,垂类AI从业者应当何去何从呢?笔者从四个方面进行了一些思考。
1. 空前的AI产物带来的行业技术挑战
由俭入奢易,由奢入俭难。
量变引起质变,继BERT以后,NLP又走到了一个新的路口。ChatGPT所展示出的空前流畅的交互体验,给NLP、甚至整个人工智能行业带来的冲击是巨大的,这一冲击与其说是ChatGPT带来的,不如说是大型语言模型(Large Language Model,LLM)带来的。相比于BERT等小型语言模型,LLM在多个NLP任务上都呈现了近乎碾压的效果:
NLU
注:这里笔者将NLU、NLI拆分为2个任务,此处的NLU仅指代语义分析、信息抽取等简单自然语言理解能力;后文的NLI指代逻辑推理能力。NLU是NLP的基础任务,其中最常见的子任务就是意图识别、信息抽取,通常位于NLP系统的最前端。BERT时代绝大部分NLP系统、尤其是对话系统的效果瓶颈就出在NLU任务上,答非所问、“听不懂人话”,都会极大地降低使用者对于NLP系统的信任程度。
而ChatGPT从问世至今,在NLU任务上极少掉链子,对于广大网友所提的问题以及问题中涉及的概念的理解都非常准确,这便是其给已有的诸多NLP系统带来的最大挑战之一。
NLG
作为生成式语言模型,GPT系列的一大亮点就在于能够输出足够流畅的“人话”。NLG能力的一个突出表现在于——对于模型确实不知道答案的问题,它也能“理直气壮”地生成一段能够以假乱真的“胡言乱语”应付过去(没错,这是优势而非劣势,这种表现正是NLG任务所追求的目标之一)。
NLI
plaintext1
2
3
4
5
6
7
8
9
10
11
12
13
14To grasp the proposed relationship between compression and understanding, imagine that you
have a text file containing a million examples of addition, subtraction, multiplication,
and division. Although any compression algorithm could reduce the size of this file, the
way to achieve the greatest compression ratio would probably be to derive the principles of
arithmetic and then write the code for a calculator program. Using a calculator, you could
perfectly reconstruct not just the million examples in the file but any other example of
arithmetic that you might encounter in the future. The same logic applies to the problem of
compressing a slice of Wikipedia. If a compression program knows that force equals mass
times acceleration, it can discard a lot of words when compressing the pages about physics
because it will be able to reconstruct them. Likewise, the more the program knows about
supply and demand, the more words it can discard when compressing the pages about economics,
and so forth.
———— Ted Chiang
《ChatGPT is a blurry JPEG of the web》与作为信息前端的NLU、信息输出端的NLG有所不同,根据知识的核心逻辑进行推理的NLI可以认为是整个人工智能领域的终极追求——智能决策能力。在ChatGPT问世后的一小段时间内,笔者其实也怀疑过其是不是只是对训练语料(整个互联网上的文本数据)进行二次生成,直到有人开始测试其解决数学题的能力,笔者才认为它已经初步具备了推理能力。
会解数学题是如何与推理结合起来的呢?我们知道,如果一个对话系统只是对训练语料进行搜索并给出回复,那么它需要事先拥有全部的语料。然而对于哪怕只是最简单的
A+B=?形式的数学题而言,枚举数据量都是无法计数的。因此,能够解决数学计算问题,很大程度上能够说明模型学习到了数学计算逻辑、具有一定的知识推理能力。Dialogue
对话系统作为一个综合型模块,涵盖了NLP中大部分的能力。要组成一个优秀的对话系统,除了需要上述的NLU、NLG、NLI三个能力之外,还必须拥有一种被称之为对话管理(Dialogue Manage,DM)的能力,也就是我们俗称的联系上下文的多轮对话能力。
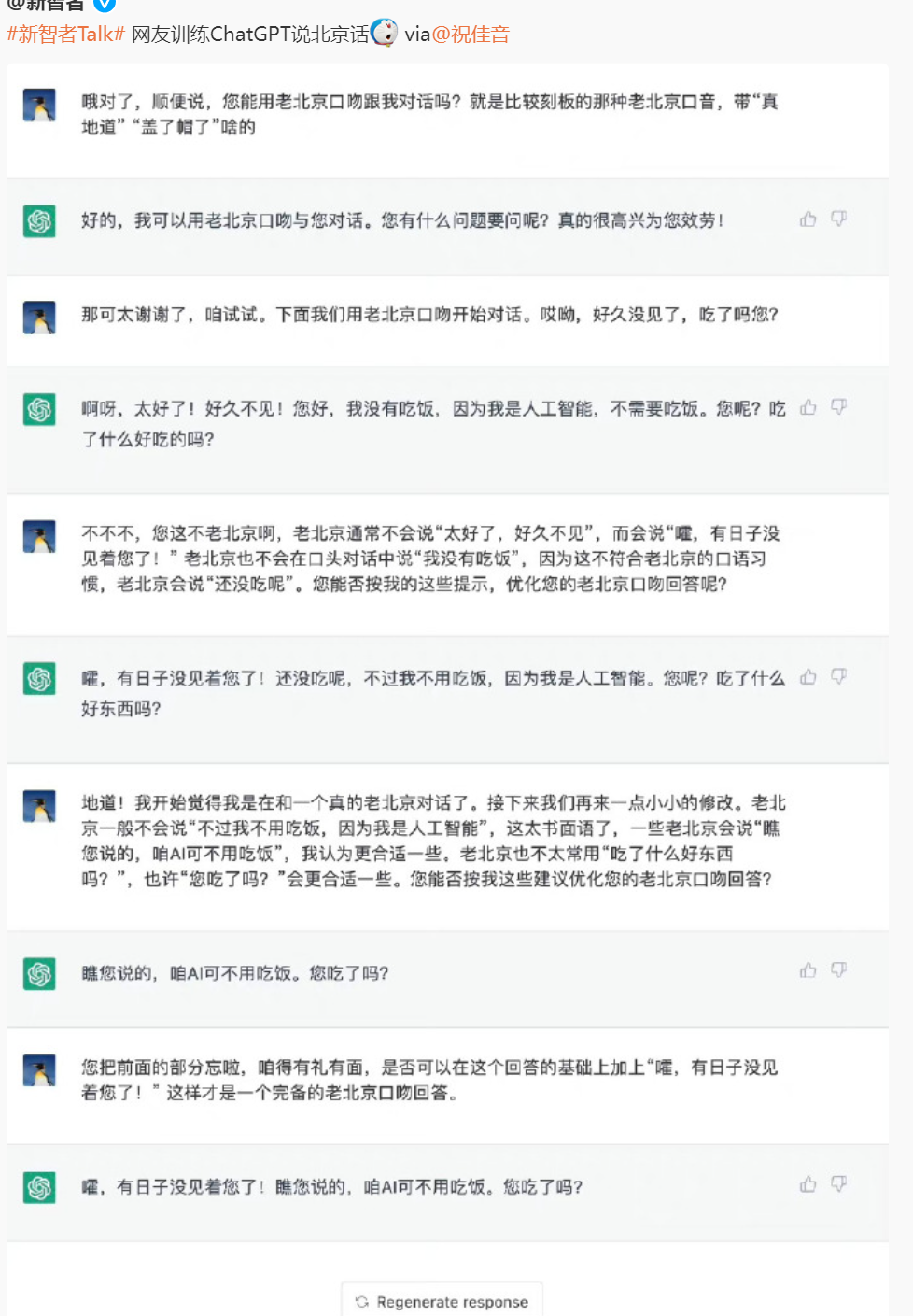
所谓对话管理,也就是根据历史对话信息,决定当前应该如何与用户进行交互。而下图所展示的一位网友脑洞大开成功教会ChatGPT说北京话的案例,则很好地说明了ChatGPT在DM上的表现也是令人惊艳的。
![]()
NL2Code
除了上面4个NLP主流任务以外,ChatGPT也展示了一些新颖的能力,编程便是其中之一。编程作为一个脑力劳动,涉及到大量的思维推理过程,若没有足够强大的NLU与NLI能力作为基础,模型很难具备根据自然语言输入来输出可执行代码的能力。然而,ChatGPT做到了这一点。
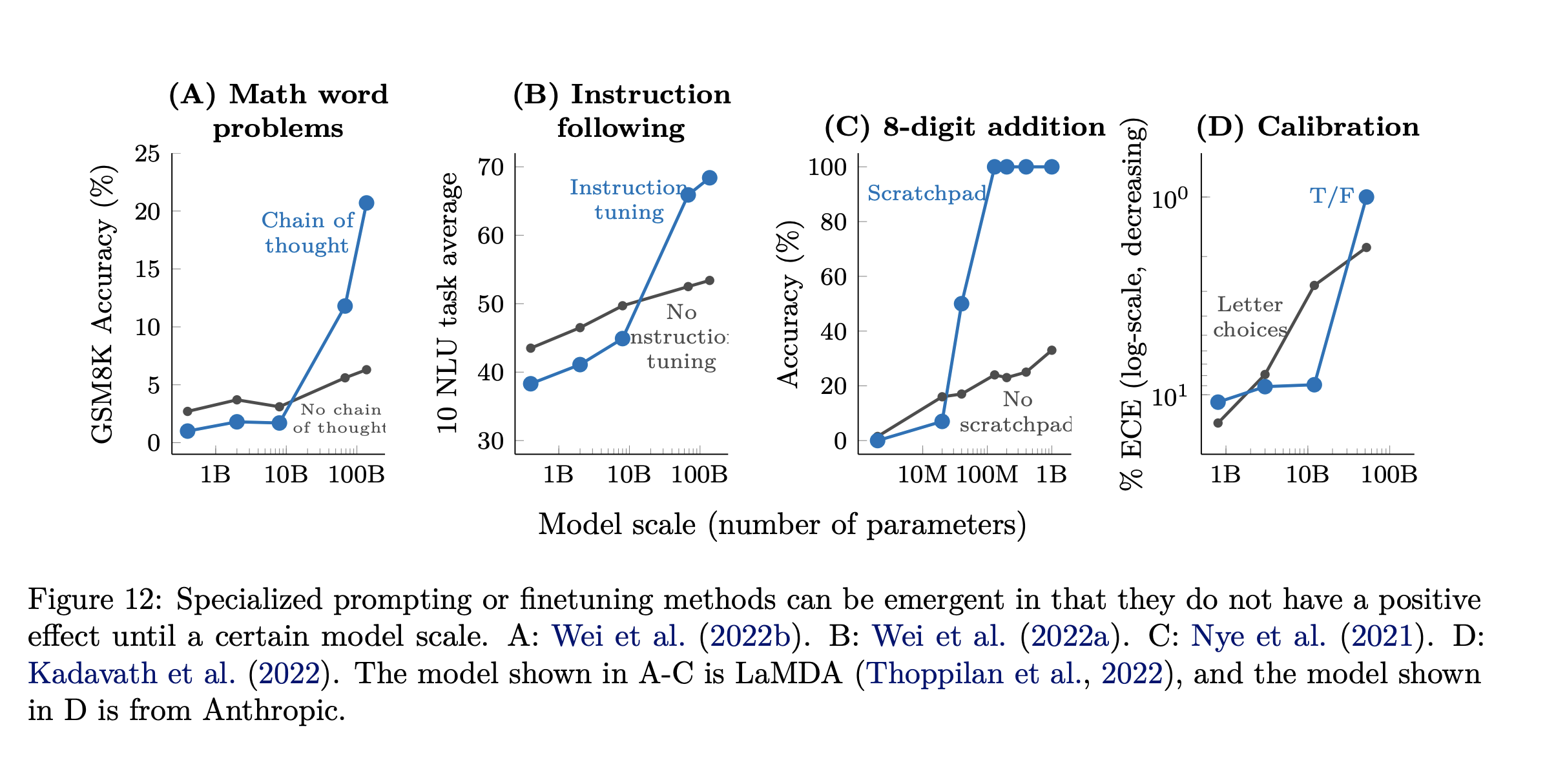
除了效果上的优越性以外,支撑模型计算所需的算力也是一个不可忽视的门槛。OpenAI发布的GPT-3、InstructGPT(ChatGPT的核心模型)系列模型,效果最佳模型的参数量高达1750亿。虽然目前我们还无从得知ChatGPT背后究竟是哪一个版本的InstructGPT,但该模型即便是最小的版本也拥有15亿的参数量,与过去1亿参数量的BERT相比,模型大了至少10倍。也就是说,算力需求也大了至少10倍,而这种算力需求的扩增却并不是大部分业界研发团队能负担得起的。以推理任务为例,下图展示了不同推理任务上各参数规模的模型的表现
2. 对待新技术,垂直行业的AI从业者需要保持理性
笔者这里所说的“垂直行业”,指的是诸如医疗、法律、教育等具有比较独立且完备的知识体系的知识密集型行业。确实,ChatGPT在多个NLP任务上都展现出了优越的效果,即便如此,部分技术乐观派所持的“有了chatGPT,这一个LLM就能替代你们现在的所有NLP模型“观点,笔者依然认为是不理性的。作为垂直行业的AI从业者,面对新模型时,我们往往会思考其可用性。具体地,需要我们思考如下2个问题:
必要性:垂直行业真的需要ChatGPT吗?
在上文中,我们分析了ChatGPT在5个NLP能力上大放异彩,但冷静下来仔细一想,在垂直行业中,我们真的需要模型同时具备这5种能力吗?让我们先分析一下垂直行业中构成AI工具用户的2大用户群体:
- 第一类用户(欠缺行业知识的普通民众):这类用户使用AI工具的主要目的在于弥补其欠缺的行业知识、辅助他们进行与垂直行业有关的决策。由于本身欠缺行业知识,该类用户对于AI工具输出的内容(决策建议或具体行业知识条文)不具备判别能力,AI工具对其而言更像是一位老师,因此要求AI工具具有较高的准确率下限。
- 第二类用户(具备一定行业知识的从业者):这类用户使用AI工具的主要目的在于提升其工作效率,由于其本身具有一定量的行业知识,因此AI工具对于他们来说更像是一个为其处理大量重复性、且对于从业者而言不具有太多技术性的工作的助理,对于AI工具的能力要求具有一定门槛。
那么,这两类用户的需求,对于上述5个NLP能力分别有什么样的要求呢?
- NLU:必需。正如上文所说,NLU是一切NLP任务的基础,如果无法从一段文本中准确获取所需的信息,那么下游一切任务的准确性都无从谈起。可以说,NLU能力是对第一类用户的基本保障。
- NLG:未必。在某些场景下,以加工过的自然语言进行输出当然能够获得更好的交互体验,但从需求而言,这只是锦上添花,而非必需。
- NLI:必需。知识密集型行业的核心竞争力在于根据行业知识进行决策,是否具备这一能力直接决定了一个AI产品是否能吸引到第二类用户。NLI能力的普遍缺乏是过去AI(尤其是NLP)产品在垂直行业从业者圈子里难以商业化的根本原因。
- Dialogue:未必。对话系统本身只是AI众多交互形式中的一种,并非所有AI工具都需要以对话形式呈现。
- NL2Code:不需要。该能力仅针对开发者。
充分性:在垂直行业,ChatGPT够用吗?
这一问题,主要针对上述的第二类用户。
在这场网民与资本的共同狂欢中,我们见过很多成功进行知识问答的样例,也见过不少失败的样例。笔者从自己有限的观测中感觉到——成功的样例多数都是能在百度、Google等搜索引擎中直接搜索到答案的问题,对于专业或小众的知识,chatGPT很容易“露怯”,古典音乐领域的从业者对chatGPT进行了测试的这篇文章就是一个很好的例子。
当然,由于观测数确实有限,笔者的这种感觉无法作为论据,且暂时也无法区分这其中是否还存在着如幸存者偏差等统计陷阱,但对于需要垂类搜索引擎才能查到的问题无法很好、很稳定地被chatGPT回答这一事实是客观存在的。
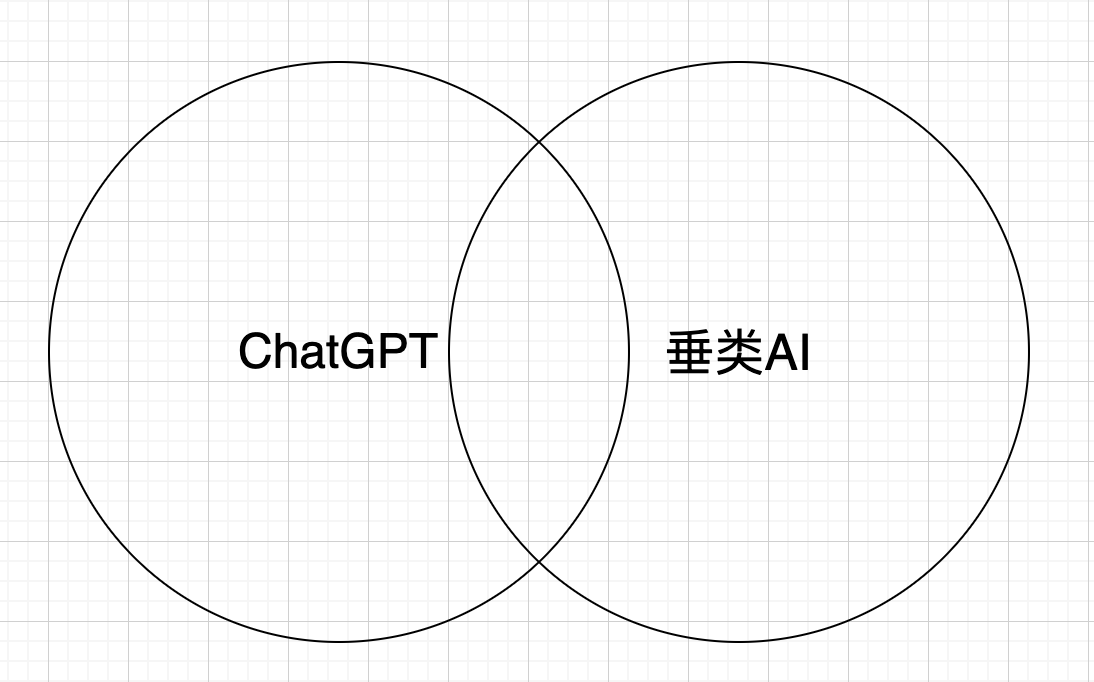
可以看到,在chatGPT所拥有的能力中,部分对垂直领域来说是过剩的,部分则依然需要加强。在笔者看来,ChatGPT与垂类AI的关系如下图所示
3. AI浪潮中产生的新机遇
ChatGPT与当时的AlphaGo一样,除了带给从业者深深的压力以外,也重新激起了圈外人对于AI、尤其是NLP的兴趣。ChatGPT在通用领域的成功,也会激发一部分垂直行业用户对于AI产品的尝试意愿,如同向死寂的湖面投入一颗石头一样,Chat也为垂直行业的企业带来了一丝商业化AI的希望。
除了商业上的机遇,笔者更重视的是ChatGPT引发的技术机遇。在笔者的朋友圈中,与ChatGPT共现最多的词就是失业、替代,甚至还有朋友认为“从此知识变得廉价”。但笔者认为,ChatGPT不但不会使知识贬值,反而会让真正的知识显得愈发珍贵。
不客气地说,由于NLU、NLG水平的限制,我们过去一直生活在一个只追求90%的时代:许多大大小小的研发团队在重复生产相同、甚至效果更弱的基础能力,加上团队资源的限制,使得大量优秀的研发力量都扑在了最底层的能力上,而那些具体场景中真正影响使用体验的“最后一公里”难题却少有团队能够有精力去处理。倘若我们已经解决、或者很大程度上解决了NLU、NLG问题呢?是否会有更多的研发力量投入到那些真正困难的、广泛细分的瓶颈任务上呢?
此时,作为在垂直领域摸爬滚打多年,对业务逻辑、行业需求都有着深入思考的行业研发团队,其行业研发知识就能体现出真正的价值。具体地,笔者认为接下来对于逻辑推理能力的集中思考与落地,将为整个人工智能行业的发展,奠定重要的理论与工业基础。
从0到1,再到追求90%,也许现在我们是时候抬头看一看100%了。
4. 革命尚未成功,同志仍需努力
从word2vec、BERT、GPT-3,再到今天的ChatGPT,我们并非首次面临这样的震撼。从不被世人看好的GPT-2,到初现锋芒的GPT-3,再到如今的ChatGPT,OpenAI对于GPT路线的坚持造就了今天的成功。而同样地,在当前的多个NLP任务中,NLI仍尚处萌芽,对于逻辑推理以及知识、尤其是垂直行业知识进行建模的坚持是否会造就下一个OpenAI?
笔者期待着那一天的到来。